- 해당 이슈는
GIN인덱스의 비용 측정에서 버그가 있다는 이슈이고, 이를 해결하기 위한 패치를 포함하고 있다. 아래의 글을 잘 읽어보자.
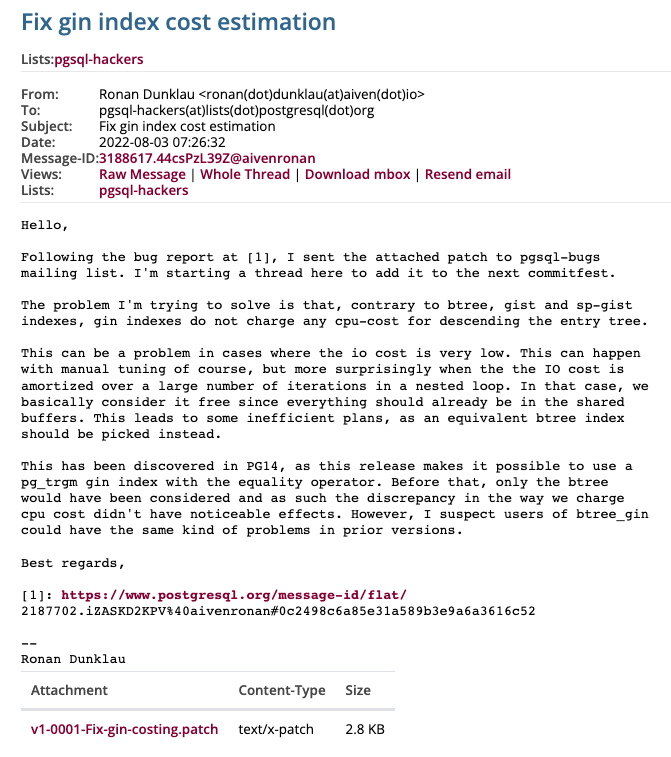
1. B+TREE와 비교해서, GIN, GIST, SP-GIST 인덱스들을 CPU 비용을 계산하지 않는다. 엔트리 트리를 내려가는 동안에... -> 이는 낮는 IO 비용을 가지고 있는 연산에서 문제가 될 수 있다.
2. 네스티드 루프에서 많은 반복에 의해서 IO 비용이 줄어들 떄 모든 것이 SHARED BUFFER 에있기 때문에 비용이 무료라고 간주한다.
3. 해당 이슈는 PG14 버전에서 발견되었으며, 해당 버전에서는 PG_TRGM, GIN 인덱스에서 '=' 연산자를 사용할 수 있다.
4. 이전에는 B+TREE에 대해서만, 고려를 하고 있었다. 따라서 BTREE_GIN 익스텐션 역시 위와 같은 문제를 일으킬 것이라고 생각한다.
-
우선 패치는
/src/backend/utils/adt/selfuncs.c에서 이루어진 것을 확인할 수 있다. -
해당 파일의 앞부분의 주석을 읽어보면, 선택도(SELECTIVITY) 함수와 표준 연산 및 인덱스 접근 메서드를 위한 인덱스 비용 추정 기능이라고 적혀 있다.
create temp table t_gin_test_tbl(i int4[], j int4[]);
create index on t_gin_test_tbl using gin (i, j);
insert into t_gin_test_tbl
values
(null, null),
('{}', null),
('{1}', null),
('{1,2}', null),
(null, '{}'),
(null, '{10}'),
('{1,2}', '{10}'),
('{2}', '{10}'),
('{1,3}', '{}'),
('{1,1}', '{10}');
set enable_seqscan = off;
explain (costs off)
select * from t_gin_test_tbl where array[0] <@ i;
select * from t_gin_test_tbl where array[0] <@ i;
select * from t_gin_test_tbl where array[0] <@ i and '{}'::int4[] <@ j;
gincostestimate함수에 디버거를 걸로 위의 스크립트를 실행시키면,gin인덱스를 사용하게 되면서gincostestimate함수가 실행되는 것을 확인할 수 있다.
-
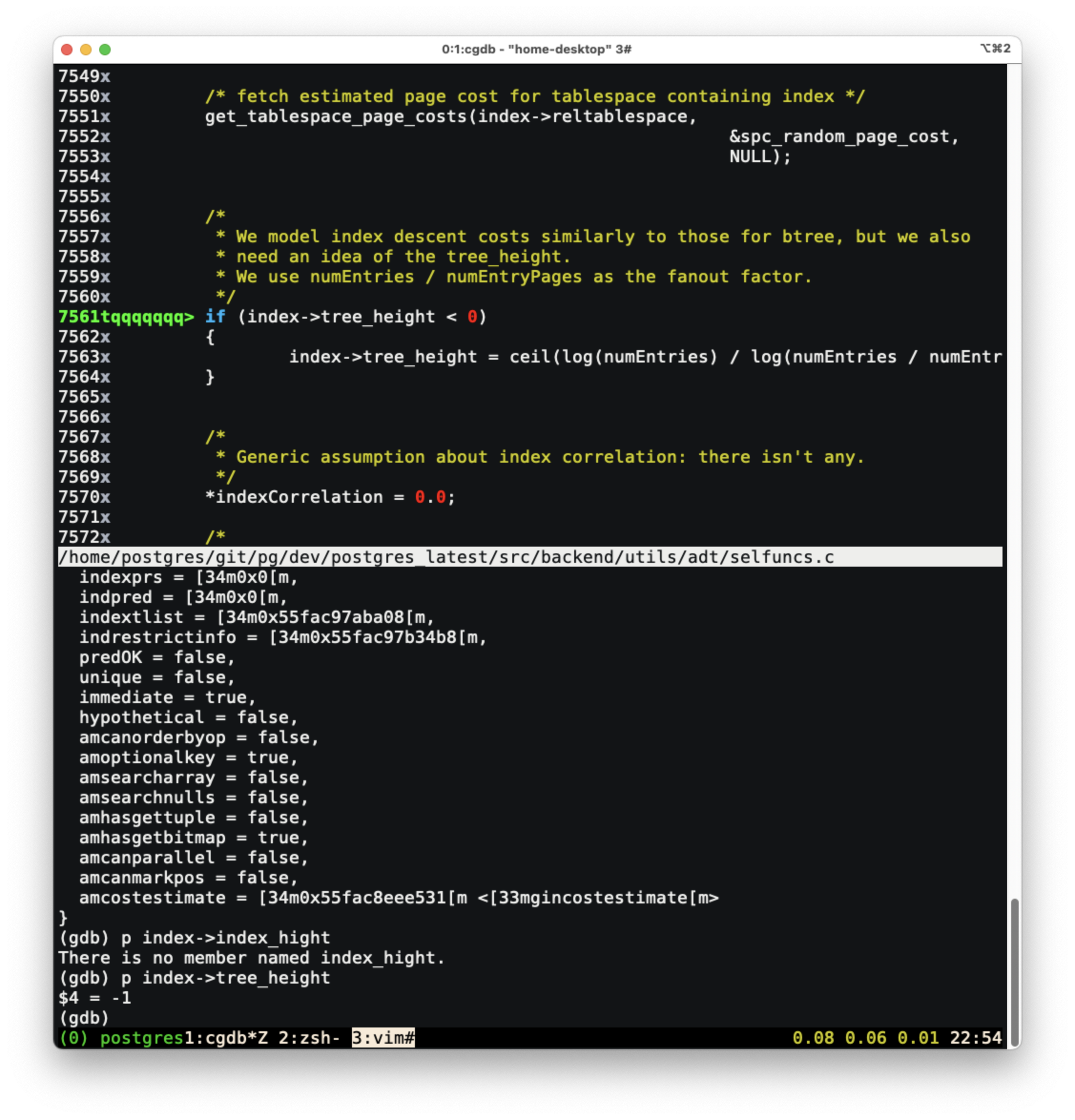
추가된 곳의 코드를 살펴보면 인덱스 정보에 있는 트리의 높이 (
tree_height) 가0보다 작으면 (구조체 주석에 보면, -1 이면 알 수 없는 값을 나타낸다.) 인덱스 트리 높이를 구해준다. -
numEntries와numEntryPages에 대해서 잘모르겠지만, 우선 이전에VACUUM이 된적이 있으면 통계정보에서 해당 정보를 얻어오고, 아니라면 직접 계산을 해준다. 해당 정보를 통해서 트리 높이를 계산해준다.
- 그리고 나서,
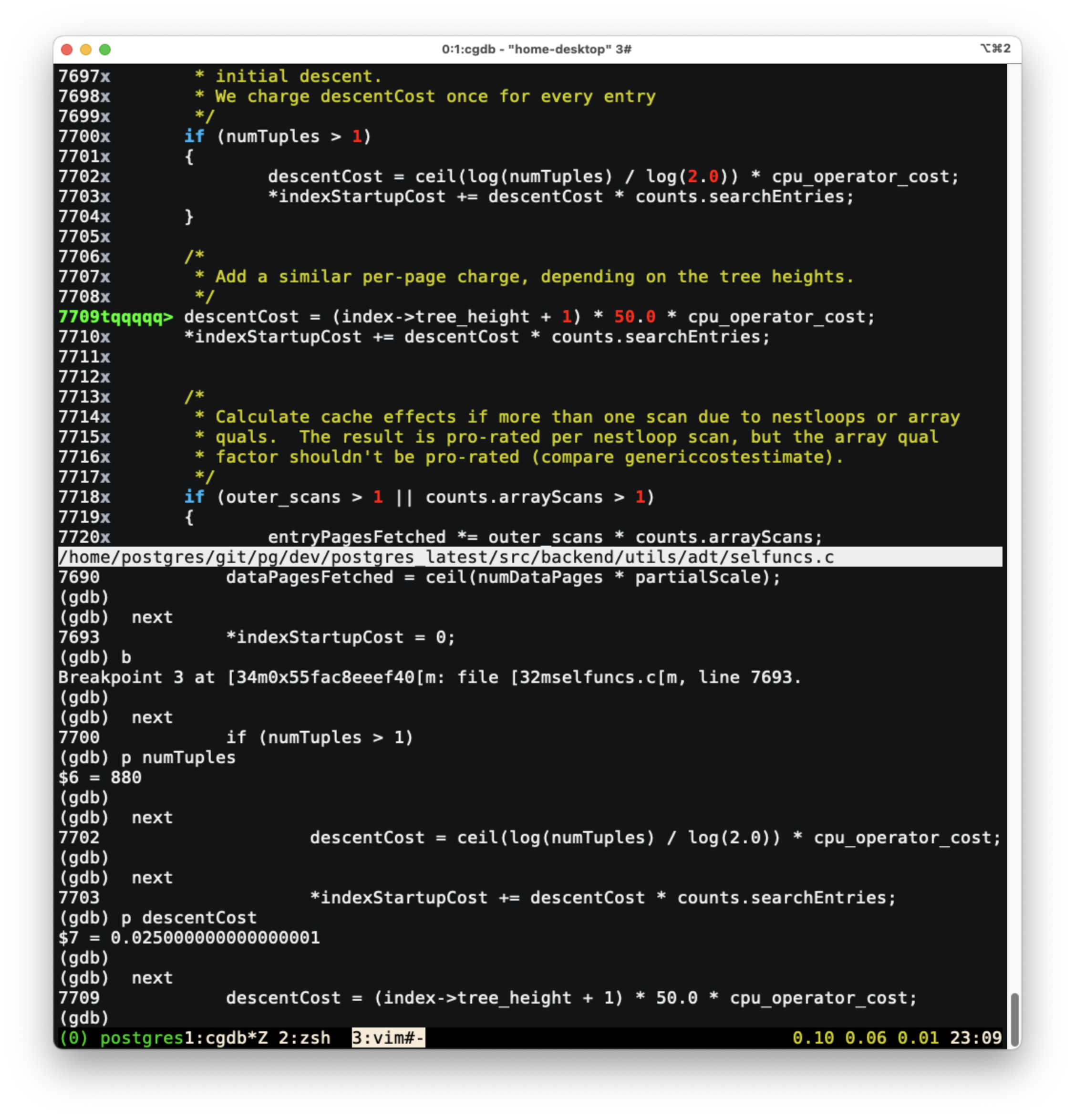
descentCost를 구해주는데, 튜플의 개수가1보다 크다면, 값을 구해준다. 위의if코드부분이 오류가 아닌가 싶었다. 왜냐하면, 위의 조건문과 상관없이 아래 코드가 실행되면서 위의 값이 덮어 쓰여지기 때문이다.
-
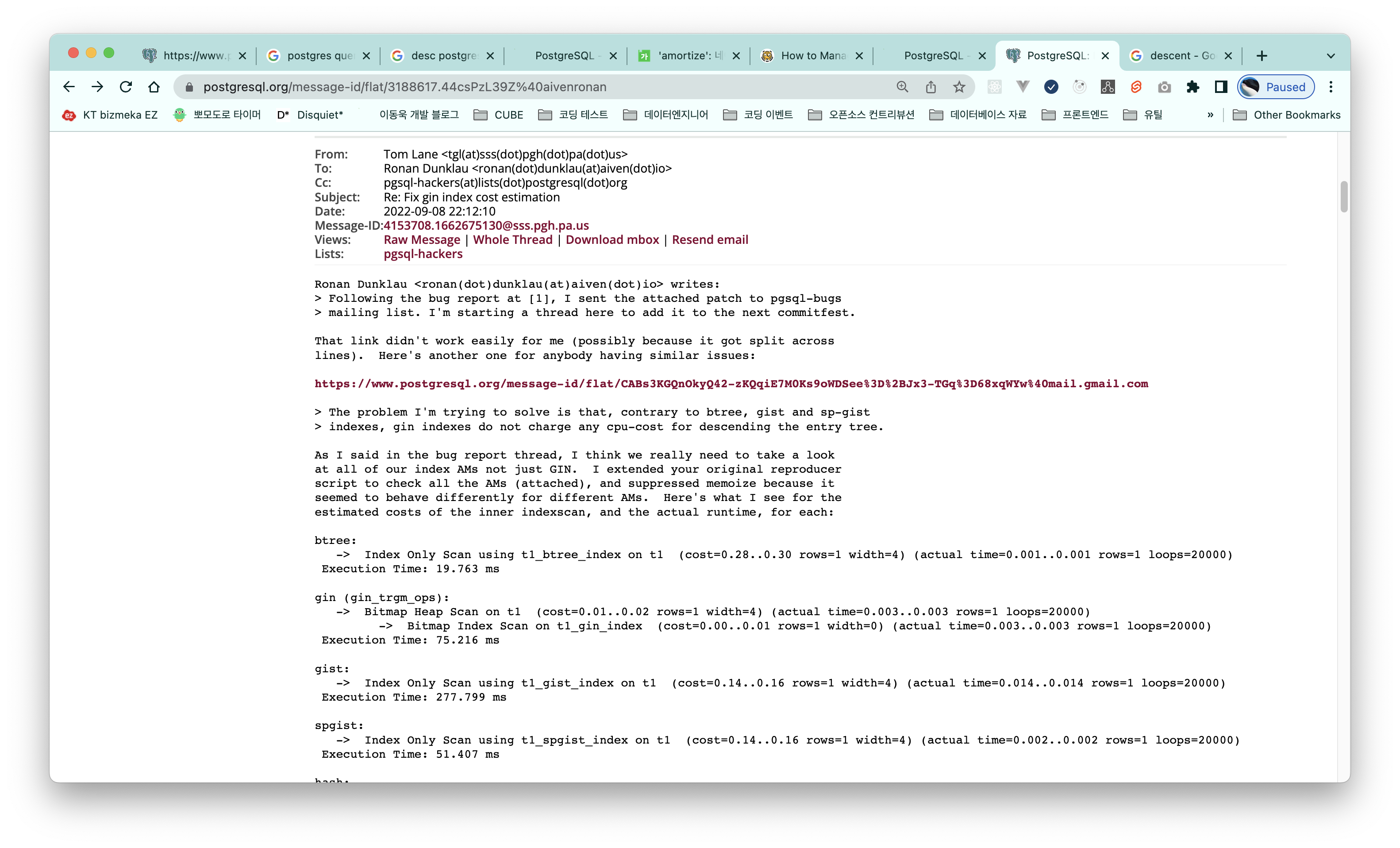
톰 레인의 답변을 보면,
gin인덱스 뿐만 아니라, 모든 인덱스에 대해서 올바르게 계산하고 있는지 확인을 해봐야 한다고 한다. -
그리고 나서 아래의 스크립트를 돌려봤는데 결과가 이상하게 나왔다고 한다.
CREATE EXTENSION btree_gist;
CREATE EXTENSION pg_trgm;
CREATE EXTENSION bloom;
drop table if exists t1,t2;
CREATE TABLE t1 (
id text
);
CREATE TABLE t2 (
id text primary key,
t1_id text
);
insert into t1 (id)
select i::text FROM generate_series(1, 1500) as i;
insert into t2 (id, t1_id)
SELECT i::text, (i % 1500 + 1)::text FROM generate_series(1, 20000) i;
ANALYZE t1, t2;
SET random_page_cost = 0.00000001;
-- SET random_page_cost = 1.0;
SET enable_hashjoin = off;
SET enable_mergejoin = off;
SET enable_memoize = off;
CREATE INDEX t1_btree_index ON t1 USING btree (id);
explain (analyze, buffers) select * from t1 join t2 on t1.id = t2.t1_id ;
DROP INDEX t1_btree_index;
CREATE INDEX t1_gin_index ON t1 USING gin (id gin_trgm_ops);
explain (analyze, buffers) select * from t1 join t2 on t1.id = t2.t1_id ;
DROP INDEX t1_gin_index;
CREATE INDEX t1_gist_index ON t1 USING gist (id);
explain (analyze, buffers) select * from t1 join t2 on t1.id = t2.t1_id ;
DROP INDEX t1_gist_index;
CREATE INDEX t1_spgist_index ON t1 USING spgist (id);
explain (analyze, buffers) select * from t1 join t2 on t1.id = t2.t1_id ;
DROP INDEX t1_spgist_index;
CREATE INDEX t1_hash_index ON t1 USING hash (id);
explain (analyze, buffers) select * from t1 join t2 on t1.id = t2.t1_id ;
DROP INDEX t1_hash_index;
CREATE INDEX t1_brin_index ON t1 USING brin (id);
explain (analyze, buffers) select * from t1 join t2 on t1.id = t2.t1_id ;
DROP INDEX t1_brin_index;
CREATE INDEX t1_bloom_index ON t1 USING bloom (id);
explain (analyze, buffers) select * from t1 join t2 on t1.id = t2.t1_id ;
DROP INDEX t1_bloom_index;
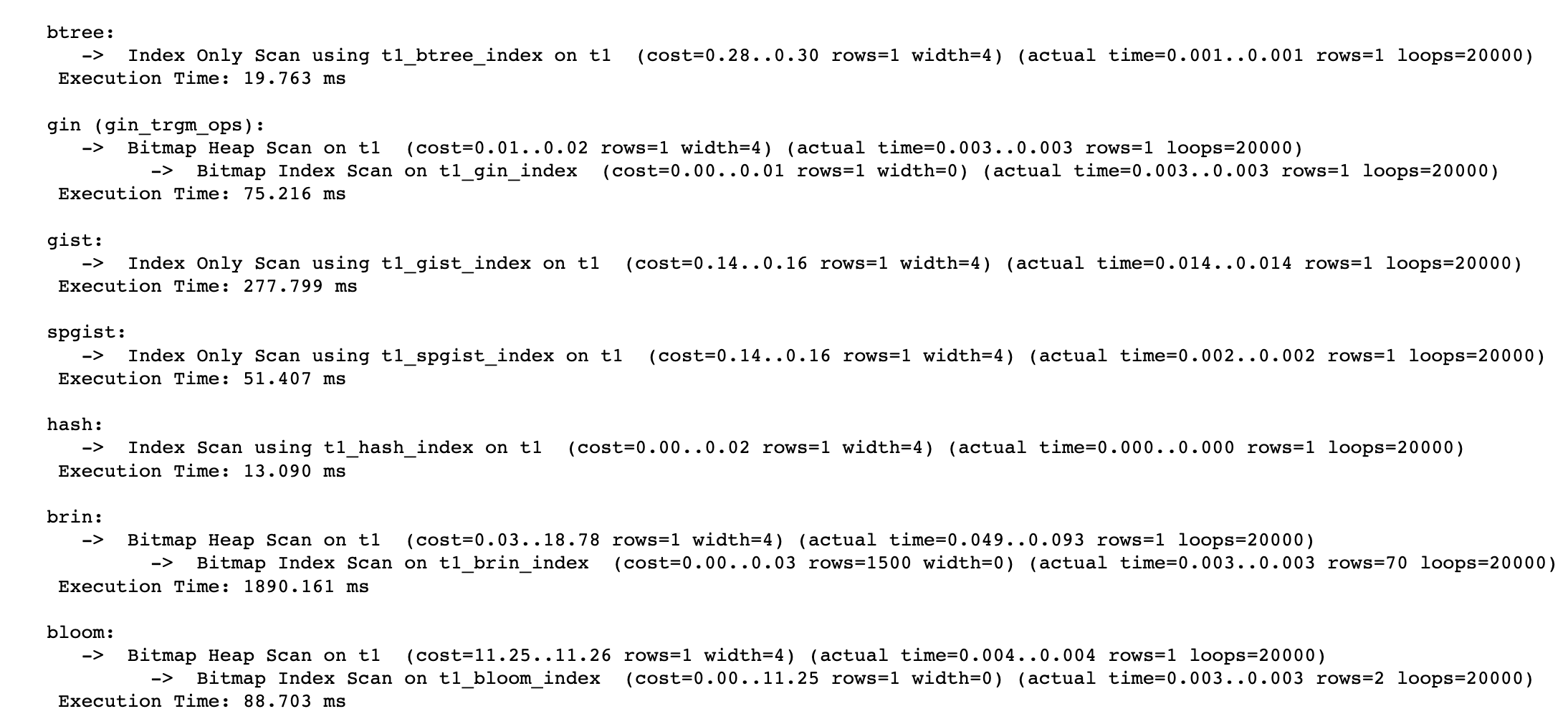
-
확실히 B+TREE를 기준으로 보았을 때, 예상 비용이 더 적게 나왔음에도 불구하고, 실제 실행시간은 훨씬 오래걸린 것을 확인할 수 있다.
-
패치에 대한 리뷰는 아래 이메일에서 이루어지는 것을 확인할 수 있다.

-
리뷰한 내용을 간략하게 요약하자면,
searchEntries에 대한 초기 탐색 비용은 계산하지만, 캐시 효과와 비슷하게arrayScans에 대해서도 확장을 해야한다고 말하는 것 같다. -
또한 트리의 높이를 구하는 계산식을 이해하지 못하겠고 (트리 높이가 1 일 때만 유효하게 보인다.) 주석이 지나치게 간단하다는 리뷰를 했다.
-
또한,
btcostestimate에 있는 주석을 중복해서 사용하는 것이 소스코드를 읽는 사람들이 추측하는 것보다는 낫다고 하면서 아래 주석을 달 것을 추천했다.
* If there are ScalarArrayOpExprs, charge this once per SA scan. The
* ones after the first one are not startup cost so far as the overall
* plan is concerned, so add them only to "total" cost.