데이터베이스에서 정렬이 중요한 이유
-
(DISTINCT, GROUP BY, ORDER BY, UNION)와 같은 많은 SQL 에서 정렬을 사용한다. 또한 조인을 할 때도 소트 머지 조인 같은 방법으로 조인을 한다.
-
만약 100GB의 데이터를 1GB의 램으로 정렬을 하려고 하면 어떻게 해야하는가? 버추얼 메모리를 사용하면 안되는가?
-
버추얼 메모리를 사용하면 실제 물리적인 양보다 더 많거나 심지어는 메모리 용량에 제한 받지 않는 것 처럼 사용할 수 있다. 또한 버추얼 메모리는 메모리 주소에 대한 참조를 디스크 입출력으로 변환하고 정렬을 시도할 떄 끔찍한 성능을 보여줄 것이다.
메인 메모리를 사용하지 않는 정렬 방법
-
- 스트리밍 방식으로 데이터를 메인 메모리로 전송하는 방법
-
- 데이터를 나누고 (메인 메모리 크기로) 그리고 나서 정복하는 방법
스트리밍 방식
싱글 버퍼링

- 데이터가 인풋 버퍼에서 아웃풋 버퍼로 이동하고 중간에 데이터를 변환하는 함수가 있는 형태이다.
더블 버퍼링
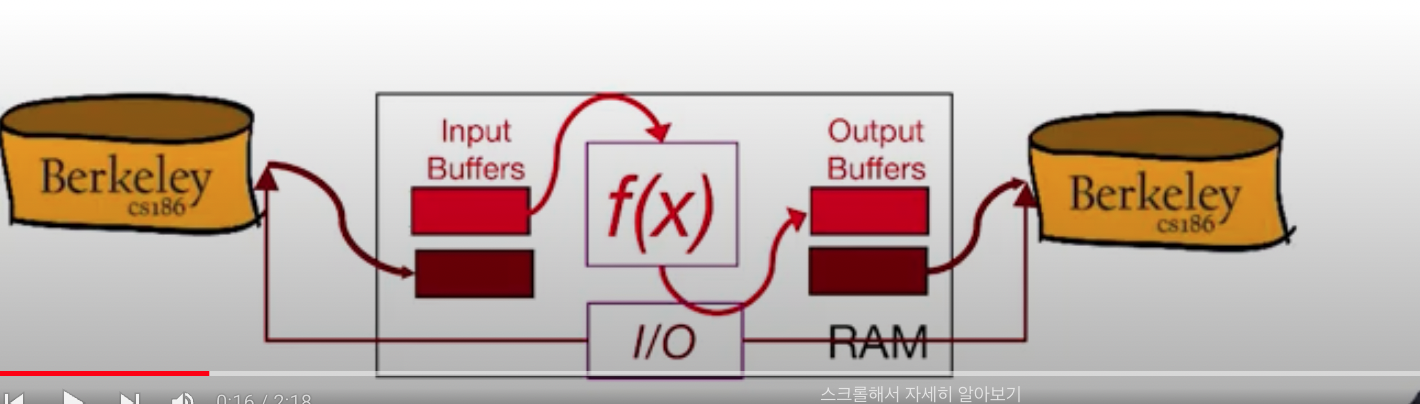
-
계산하는 부분과 I/O를 처리하는 부분을 두 개의 스레드에서 처리하는 것이다. I/O 작업은 블록킹 되므로 백그라운드에서 동작한다.
-
더블 버퍼링 방식은 정렬 뿐만 아니라, 스트리밍에서 많이 사용한다.
정렬과 해싱
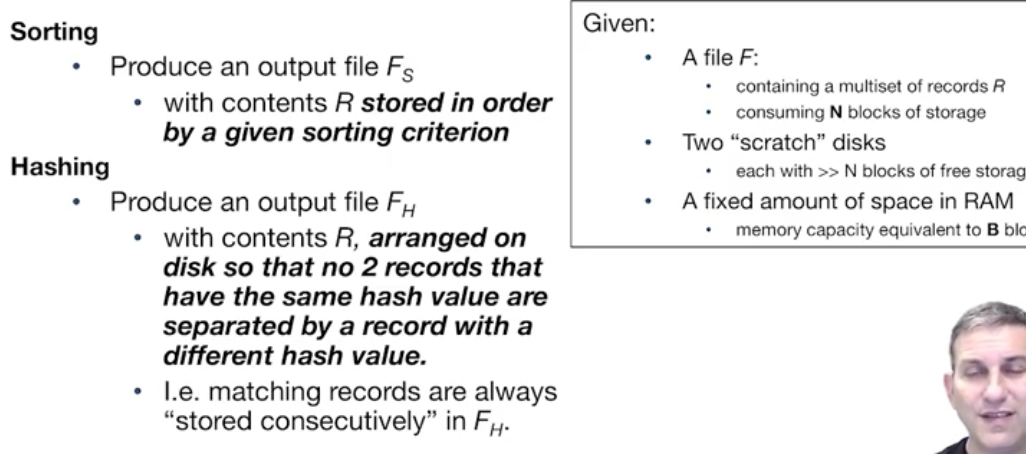
-
정렬 : 정렬 키 값을 기준으로 정렬된 파일을 반환한다.
-
해싱 : 동일한 해시 값을 가진 2개의 레코드가 다른 해시 값을 가진 레코드로 분리되지 않도록 파일을 정렬함. 일치하는 레코드는 항상 연속적으로 저장된다.
정렬 2 - WAY
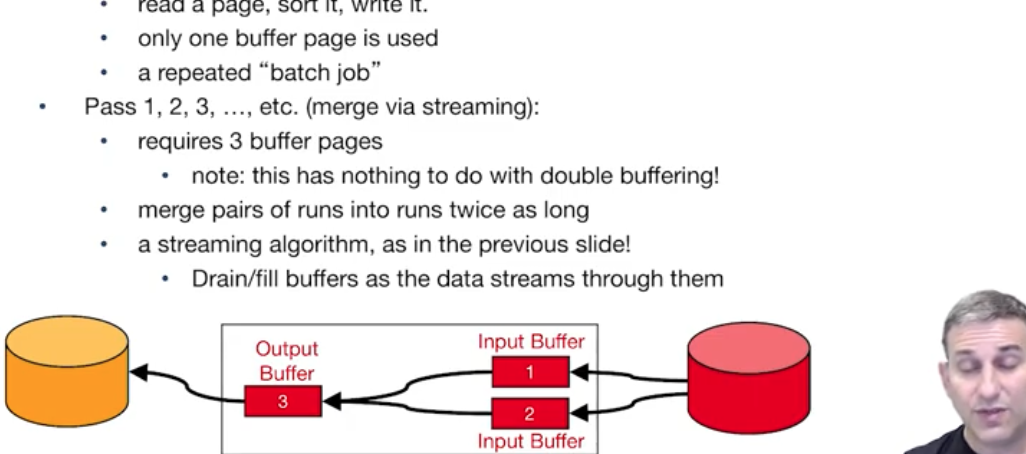
- 페이지를 읽고, 정렬하고 다시 저장하는 방식이다. 더블 버퍼링과는 상관이 없다.
정렬 - 외부 정렬
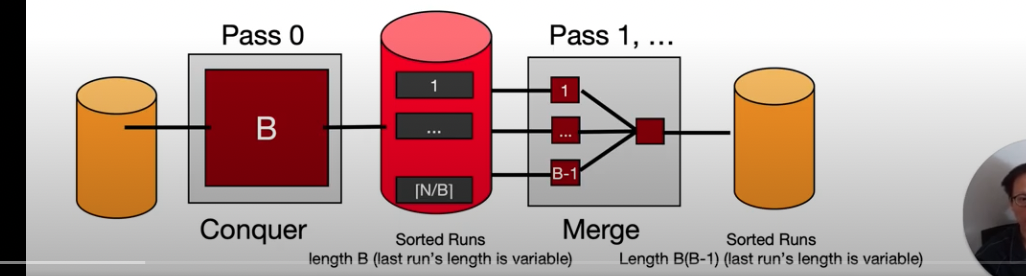
- 외부 정렬 방식은 처음에 버퍼 크기 만큼 나누고 나서, 이를 서로 병합하는 과정을 가진다.
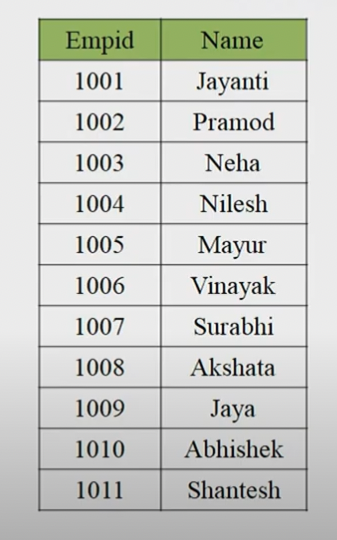
- 예를 들어서 다음과 같은 데이터가 있다고 가정을 하였을 때 각 버퍼 크기 만큼 나눈후에, 정렬을 한다.
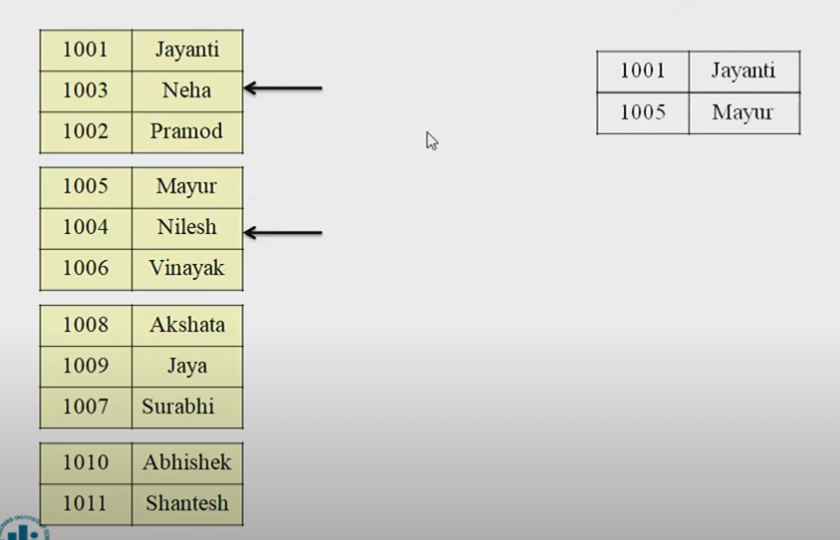
- 그리고 나서 정렬된 버퍼끼리 병합을 하는데, 버퍼 상위에 있는 데이터를 화살표로 가리키면서 서서히 내려온다. 이렇게 하면 정렬된 데이터를 얻게 된다.
해싱
-
해싱은 정렬이 필요하지 않은 경우에 사용되는 방법이다. 중복을 제거하거나 GROUP BY를 사용할 때 말이다.
-
GROUP BY에 따른 집계를 할 때 키에 따른 데이터의 집합이 필요한 것이지 정렬이 필요한 것은 아니기 때문이다.
-
해싱의 경우에도 두 단계로 나누어 진다. 바로 분할과 정복이다.
분할 (DIVIDE)
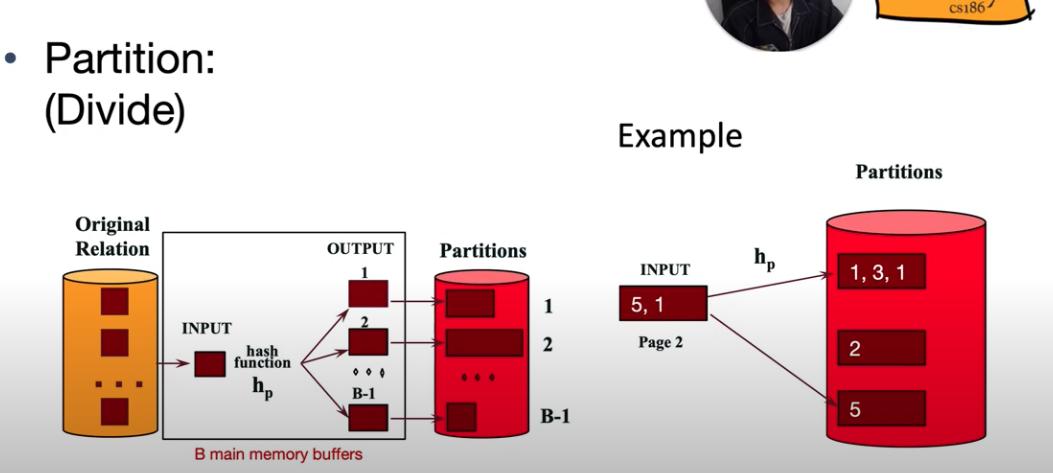
- 해시 함수에 의해서 각 값은 버킷에 담기게 된다.
정복 (CONQUER)
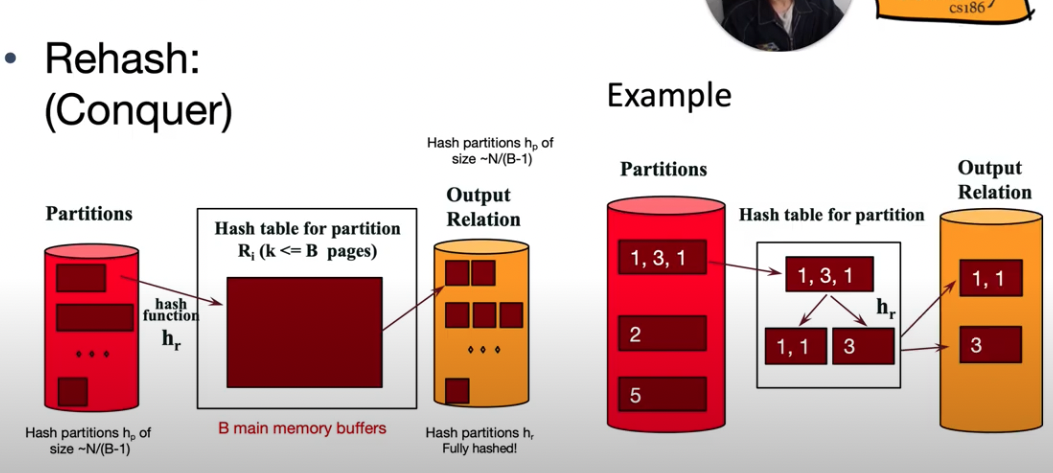
- 해시 테이블에 담긴 값을 다시 해싱을 하여 분류한다.
참고 문헌
>> Home