인덱스가 지원하는 연산
- 동등 조회 (=)
- 범위 조회 (<, >, <=, >=, BETWEEEN)
- B+TREE 인덱스는 위의 두개의 연산을 모두 지원하지만, 해시 인덱스는 오직 동등 연산만 지원을 한다.
- 그 밖에 다양한 데이터 종류를 처리하기 위한 많은 종류의 인덱스가 종류한다. (R-TREE, KD-TREE, GiST)
인덱스 키와 정렬
-
B+TREE와 같은 정렬된 인덱스는 키를 기준으로 사전 순서대로 정렬된다.
-
복합 인덱스의 경우에는 만약 (k1, k2)로 이루어진 경우에는 (k1, k2) 이후에 오는 컬럼에 대해서 동등 연산이나, 범위 연산을 하게 된다.
-
이후에 몇까지 예제를 보여줄 텐데, 초록색으로 표시된 부분은 인덱스가 범위 접근을 할 수 있다는 뜻이고 빨간색으로 표시된 부분은 인덱스가 범위로 접근하지 못한다는 뜻이다.
-
먼저 <AGE, SALARY>에 대해서 복합 인덱스가 있다고 가정을 하자.

- 만약
AGE=31 & SALARY=400인 조건에 대해서 인덱스로 빠르게 조회가 가능한지 묻는다면 가능하다. 먼저 31을 빠르게 찾고 나서, SALARY로 정렬되어 있기 때문에 빠르게 찾을 수 있다.
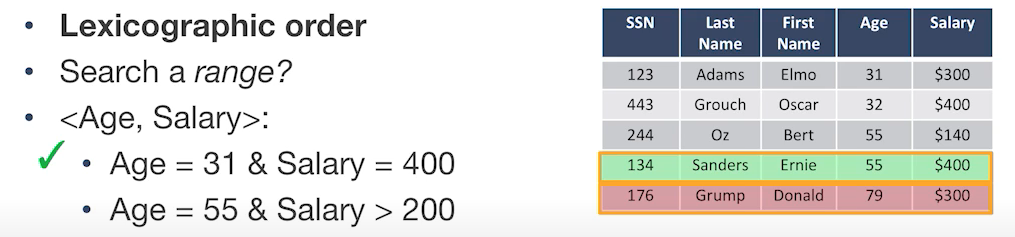
- 만약
AGE=55 % SALARY > 200인 경우에 대해서 인덱스로 빠르게 조회가 가능한지 묻는다면 이 역시도 가능하다. 위와 같은 이유로 SALARY 역시 정렬되어 있기 때문이다.

-
만약
AGE > 31 & SALARY = 400을 찾는다면 인덱스로 빠르게 조회할 수 없다. 왜냐하면, AGE가 같지 않은 상태에서 SALARY는 더 이상 정렬 상태임을 보장할 수 없기 때문이다. 따라서 AGE에 따라서 인덱스 범위 연산을 하게 된다. -
이와 같은 이유로
SALARY = 300또한 인덱스를 효율적으로 사용하지 못한다.
데이터 엔트리 저장소
- 세가지의 구현 방법이 있다. 첫 번째는 값으로 저장하는 것이고 두번째는 값을 가리키는 참조를 생성하는 것이다. 마지막은 리스트 형태로 참조하는 것이다.
1. 값으로 저장되는 형태
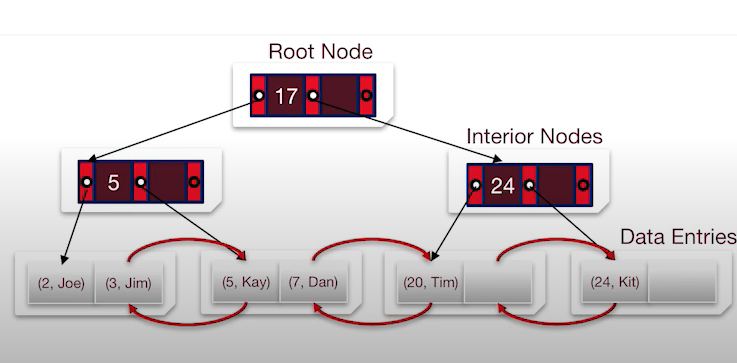
- 포인터가 필요없는 형태이다. 리프 노드에 실제 레코드가 저장되어 있으며 키와 값을 분리할 필요가 없다.
2. 참조로 가리키는 형태
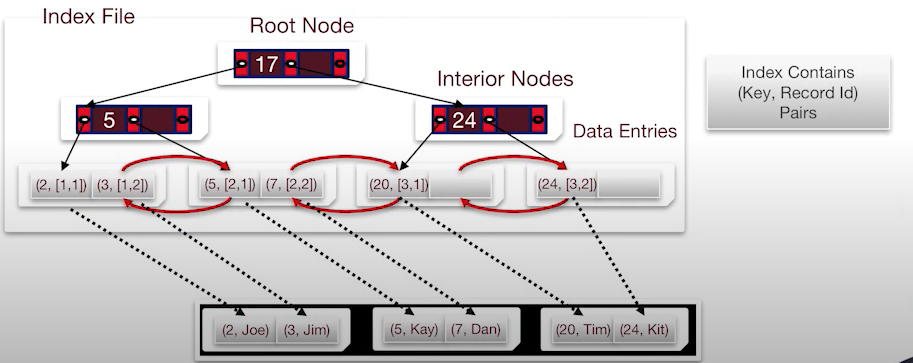
-
위와 같은 형태로는 우선 키 값으로 데이터를 찾아가면 해당 데이터에 페이지 아이디랑 슬롯 아이디가 적혀 있는 형태이다.
-
예를 들어서, (2, JOE)을 찾는다면 인덱스로 키값이 2인 곳을 찾아가면 데이터에는 [1, 1]이 들어있다. 이가 뜻하는 것은 페이지 1, 슬롯 1을 찾아가라는 뜻이다. 아래 그림에 나와있듯이 해당 위치에 가면 값을 찾을 수 있다.
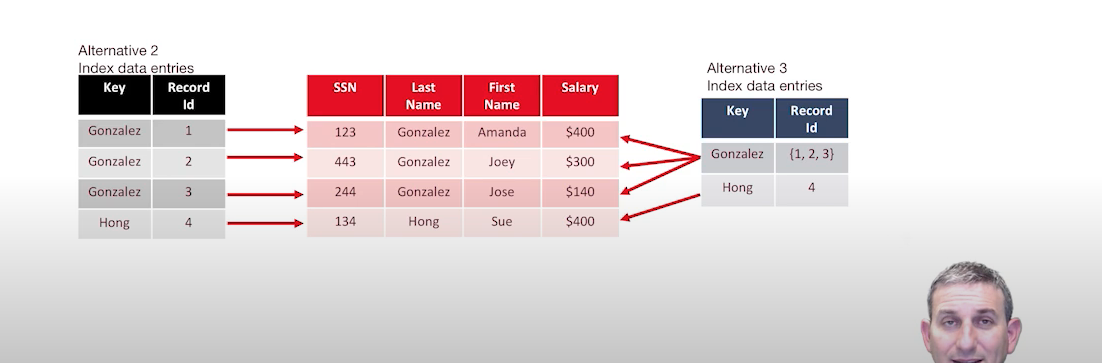
3. 하나의 키로 여러 레코드를 참조하는 형태
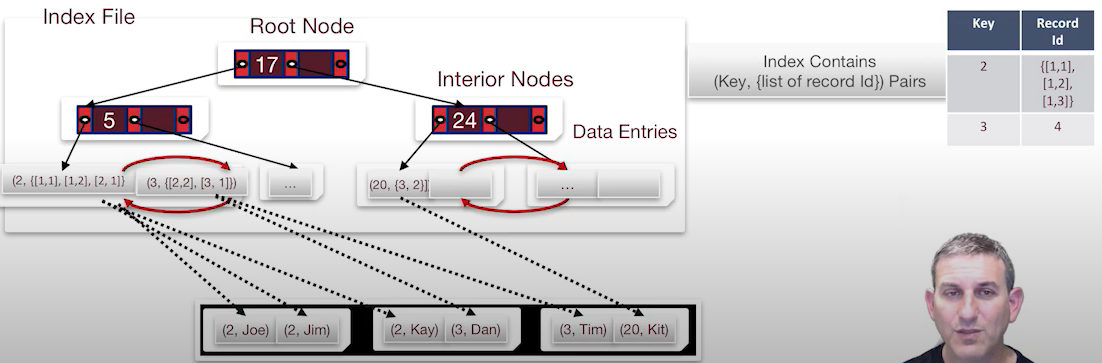
-
하나의 키가 많은 레코드를 매칭할 수 있는 구조이다.
-
이러한 형태는 키에 따른 중복 데이터가 많은 경우에 유용하다.
2번과 3번의 차이점
-
인덱스를 통해서 데이터를 참조하는 형태는 하나의 테이블의 여러가지 인덱스를구현하는데 중요하다. 그렇지 않으면 인덱스를 생성할 때마다 튜플을 복제해서 만들어야 할 것이다.
-
또한, 데이터를 참조하는 구조가 아니라면, 테이블의 데이터를 업데이트 할 때마다 엄청난 부하가 생길 것이다.
-
왼쪽의 경우에는 인덱스가 가리키고 있는 레코드와 일대일로 매칭이 되지만, 오른쪽의 경우에는 인덱스가 여러 개의 레코드를 가리키고 있는 형태이다.
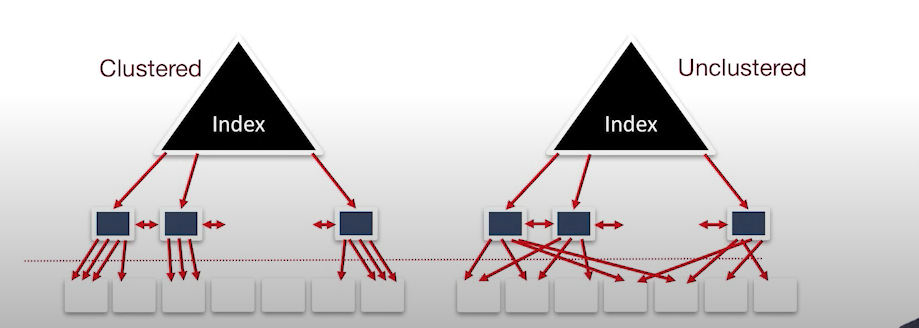
클러스트 인덱스와 클러스트 되지 않은 인덱스
-
위에서 보았던 2, 3번 형태의 참조하는 형태의 인덱스는 클러스트 되거나 클러스터링 되지 않은 인덱스 형태로 만들 수 있다.
-
클러스트된 인덱스를 만들려면 먼저 힙 파일을 정렬해야한다, 클러스터링 된 인덱스는 접근하려는 힙 파일이 순차적으로 되어있지만, 클러스터링 되지 않은 인덱스는 힙파일 순서가 정렬되어 있지 않아서, 이곳 저곳 가리키고 있는 모습을 확인할 수 있다.
-
클러스트 되지 않은 인덱스를 통해서 접근하는 경우에는 더 많은 페이지에 접근해야하므로, 더 많은 I/O가 발생한다.
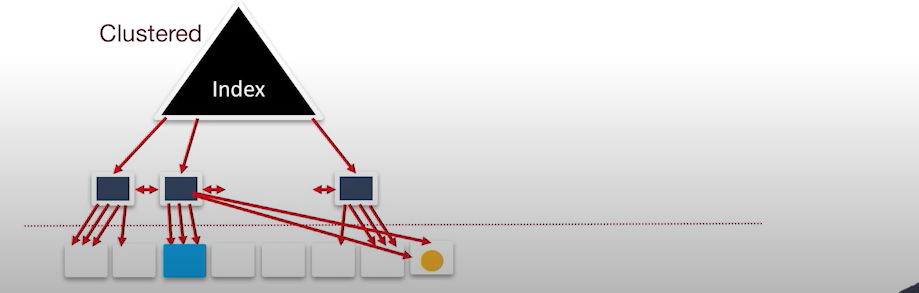
클러스트된 인덱스에 데이터가 삽입 되는 경우
-
삽입하려는 곳에 공간이 빈다면, 바로 삽입하면 되지만, 그렇지 않은 경우에는 새로운 블록을 생성하게 되고 그곳을 가리키게 된다.
-
따라서 많은 데이터가 삽입되면 힙 파일 정렬 구조는 깨지게 되며 다시 힙 파일을 정렬해줘야한다.
-
클러스터링 된 인덱스는 더 적은 I/O 를 통해서 더 빠른 조회가 가능하다. 또한 범위를 조회할 때 더 빠른 특징을 가지고 있다.
-
하지만 이를 유지하는데 많은 비용이 든다는 단점이 있다. 왜냐하면 업데이트 될 떄마다 구조가 깨지기 때문이다.
-
따라서 많은 업데이트 연산 후에 백 그라운드 연산으로, 정렬을 다시 해주거나, 힙 파일은 새롭게 더해지는 레코드를 위해서 오직 2/3 만 채우는 식으로 최적화를 한다.
인덱스 키로 길이가 변하는 키를 사용하였을 때

- 이전에는 길이가 변하지 않는 정수형을 키로 사용하는 예제를 다루었지만, 이번에는 문자열 같은 가변 데이터를 키로 사용하였을 떄 어떨지를 다루어보겠다.
PREFIX로 키를 압축시키는 방법

-
루트나 중간 노드의 키들의
PREFIX를 뽑아서 저장하는 방식이다. 하지만 이 방식은 키에 따라서 균일하게 파티셔닝이 안된다는 단점이 있다. -
따라서 리프 노드 부터 압축하는 방식을 사용하기로 한다. 이 방식에서는 분할 할 때 최소의
PREFIX를 결정하고 나서 위로 복사하여 올린다.
PREFIX & SUFFIX로 키를 압축하는 방법

- 많은 키들이
PREFIX로 하였을 떄 많은 공통된 부분이 있다. 따라서 공통된PREFIX를 헤더로 보내고 남은SUFFIX만 저장하는 방식이다.
참고 문헌
>> Home