데이터에 접근하는 두 가지 방법
-
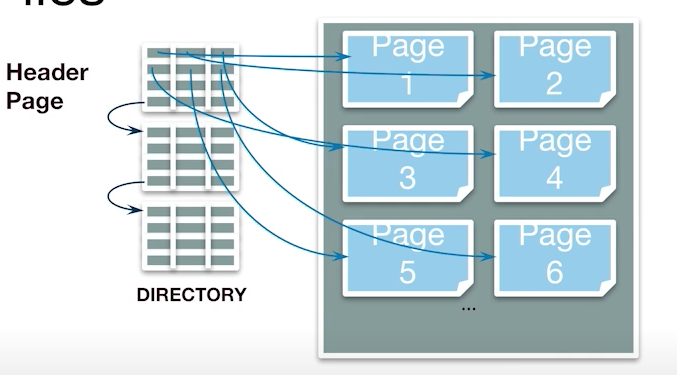
데이터에 접근하는 첫 번째 방법은 바로, 레코드 아이디(페이지 아이디, 슬롯 아이디)를 이용하는 방법이다. 레코드 아이디는 페이지 아이디와, 슬롯 아이디로 구성 되어있으며 이를 통해서 페이지를 찾아 갈 수 있으며 슬롯을 통해서 튜플을 찾을 수 있다.
-
두 번째 방법은, 페이지 시작 부분부터 모두 스캔하는 방법이다. 하지만 이런 방법은 모든 데이터를 접근해야하기 때문에 좋지 않다.
인덱스
-
인덱스란, 데이터를 키를 통해서 매우 빠르게 찾음과 동시에 변경할 수 있는 자료구조이다.
-
인덱스는 많은 연산을 지원하며, 데이터의 종류 (사진, GIS, 비트맵)에 따라서 다양한 종류의 인덱스들이 있다.
-
데이터들은 인덱스 안에 저장이 되고 일반적으로 다음과 같은 형태로 저장된다. (키, 레코드 아이디) 키를 통해서 레코드 아이디를 확인할 수 있고 레코드 아이디에는 (페이지 아이디, 슬롯 아이디)가 저장되어 있으므로 슬롯 아이디를 통해서 데이터를 찾을 수 있다.
-
인덱스에는 B+ 트리가 일반적이지만, 해시 인덱스도 많이 사용된다. 그 밖에 R TREE, GiST 등등 많은 종류의 인덱스가 있다.
인덱스의 기본 구조
- 페이지를 연결하기 위해서 포인터를 가져야 하는가? 에 대한 질문의 답은 아니다이다. 왜냐하면 페이지들은 논리적인 순서대로 디스크에 정렬되어 저장되기 때문이다.
-
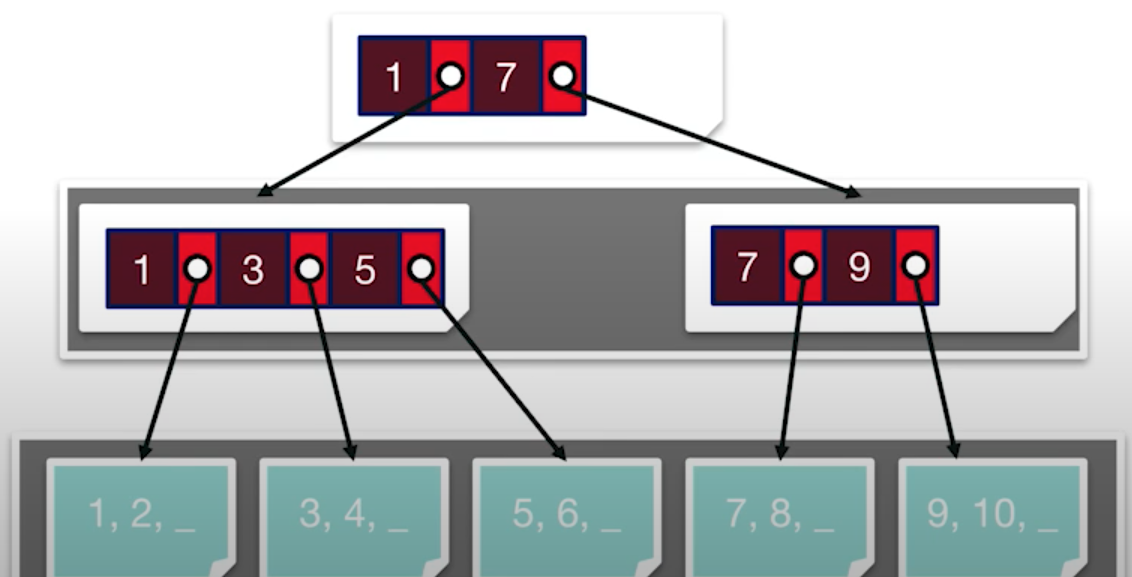
위의 그림은 키에 의해서 정렬된 (키, 페이지 아이디)의 인덱스 구조이다. 실제 데이터보다 적은양의 데이터로 페이지를 가리키고 있다.
-
키보다 같거나 작은 값은 왼쪽에 저장되며, 같거나 큰 값은 오른쪽에 저장 된다.
-
그리고 데이터를 검색할 때 루트 인덱스부터 시작해서, 아래로 내려가는 구조이다.
향상 시킨 인덱스
-
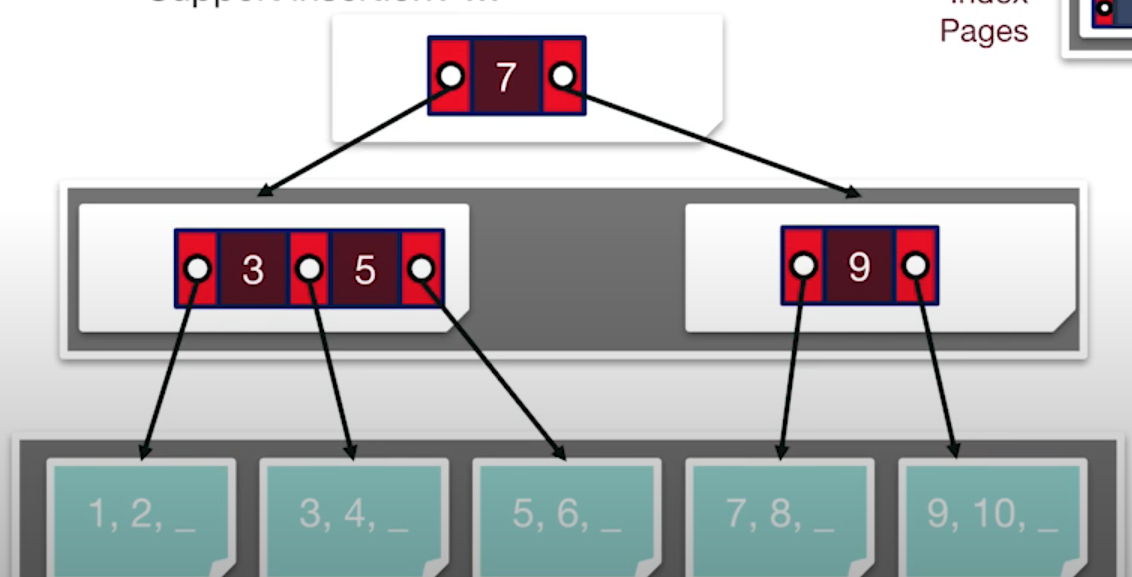
위의 구조를 조금 더 발전 시키는 구조는 위와 같다. 가장 왼쪽에 있는 값을 제거하였는데 이유는 인덱스에 있는 값보다 작으면 왼쪽에 있다는 것을 알 수 있기 때문이다.
-
따라서 적은 공간을 사용하는 만큼 더 많은 데이터를 저장할 수 있다.
-
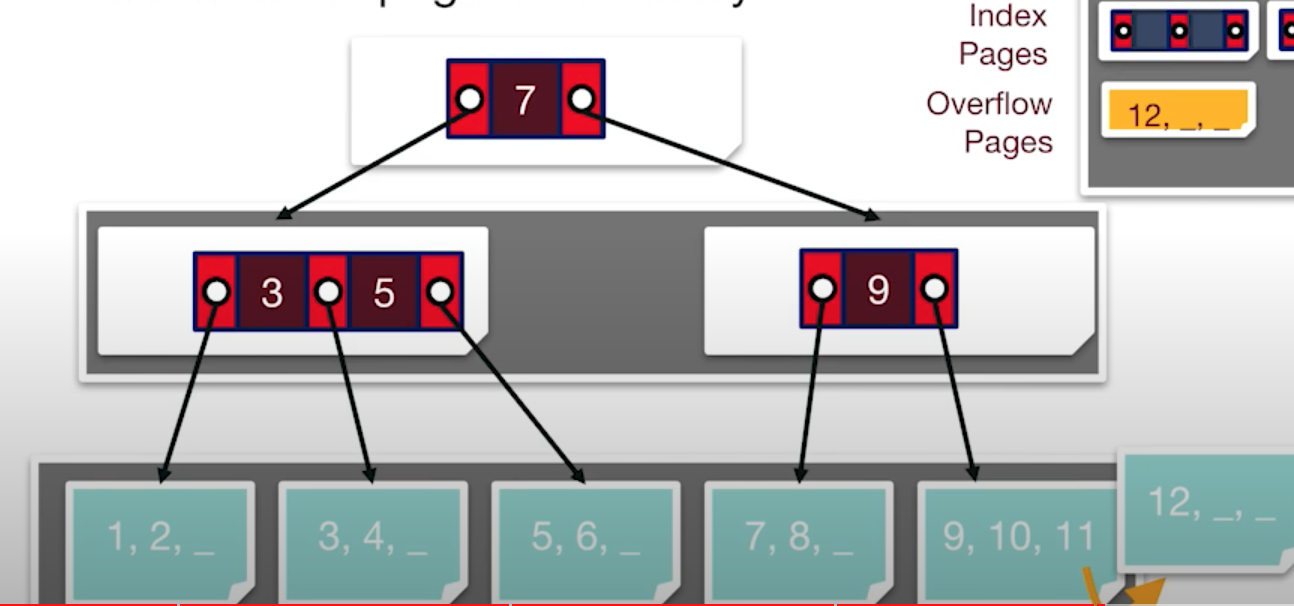
이러한 구조에서 데이터를 더 많이 추가한다고 가정을 해보자. 만약 11과 12를 추가한다고 가정을 해본다면, 위와 같은 그림이 될 것이다. 11까지는 공간이 남아서 저장을 할 수 있지만, 12는 더 이상 저장할 공간이 없다.
-
따라서, 페이지를 하나 더 생성하고, 저장한다. 그리고 이전에 저장하려고 했던 페이지에서 새로 생성한 페이지를 가리켜서 데이터에 접근할 수 있도록 한다. 이러한 방식을 ISAM이라고 한다. ISAM 방식은 예전에 IBM 회사에서 사용했던 구조이다.
-
이러한 방식의 단점은 데이터 추가가 많이 일어날 수록, 링크드 리스트 형태가 되어, 데이터에 접근하는데 비효율적이게 된다. 이러한 비효율적인 구조를 극복하기 위해서 나온 데이터구조가 바로 B+TREE이다.
B+TREE
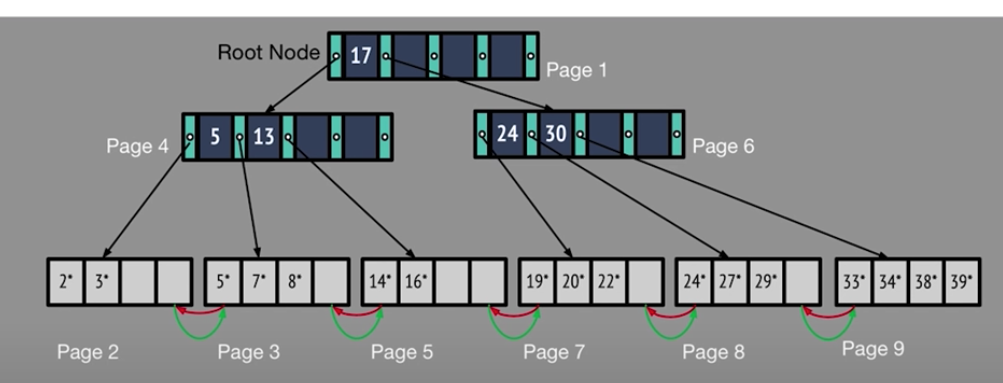
- B+TREE는 매우 동적인 데이터 구조이며, 효율적인 삽입과 삭제 연산이 가능하다.ISAM 방식은 LEAF 노드를 증가 시키는 구조인데 반해서, B+TREE 방식은 데이터가 증가 함에 따라서 루트 노드 및 중간 노드가 증가된다.
데이터 검색
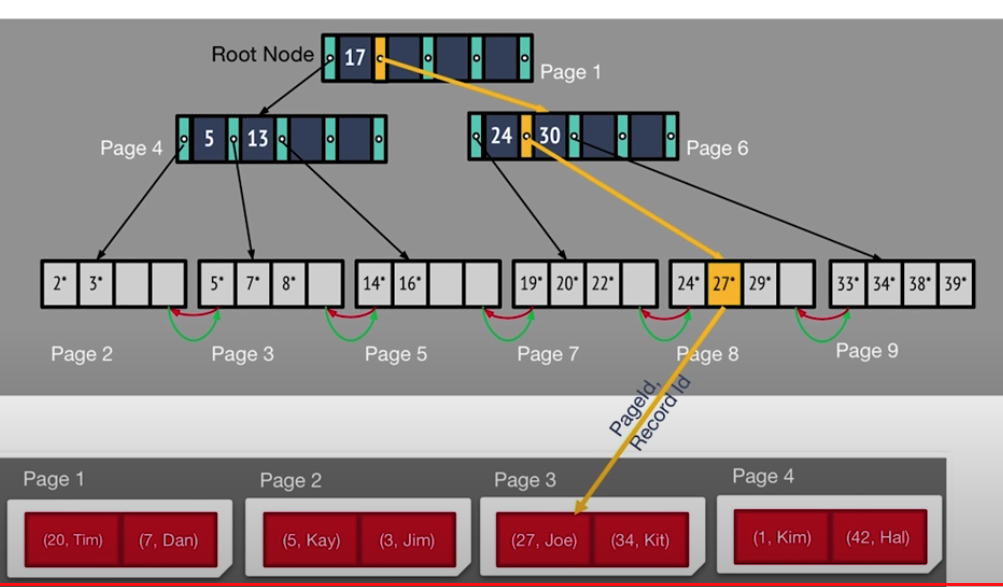
- 데이터를 찾아가는 과정은 우선 루트 노트에서 부터 시작해서, 찾으려고 하는 키가 크고 작음을 비교하며 검색한다. 리프 노드에 도달해서, 해당 레코드 아이디로 원하는 데이터에 접근할 수 있다.
데이터 삽입
- 데이터 삽입의 경우에는 조금 복잡하다. 삽입하려는 노드가 꽉찬 경우에는 분리를 해준다.
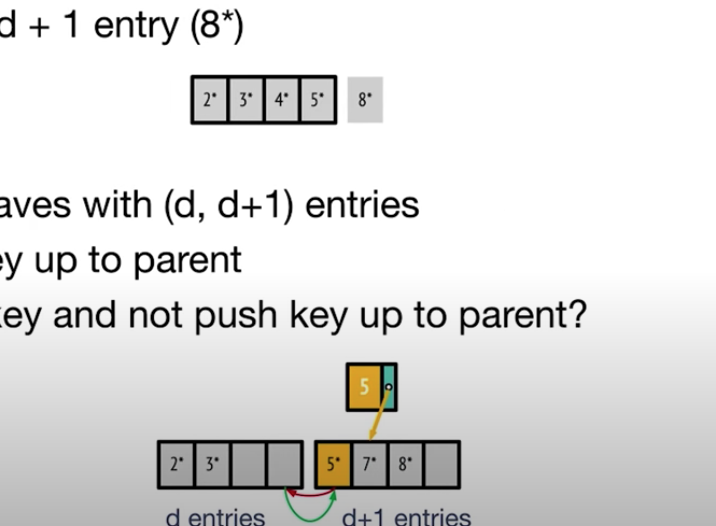
- 아래의 경우
8을 리프노드에 추가하려고 하는데 자리가 없다. 따라서, (D, D + 1) 이 경우에는 새로운 리프노드 자리를 만들고 2, 3을 왼쪽에 5, 6, 7을 오른쪽에 배치한 후 가운데 값인 5의 값을 복사하여 위로 올린다.
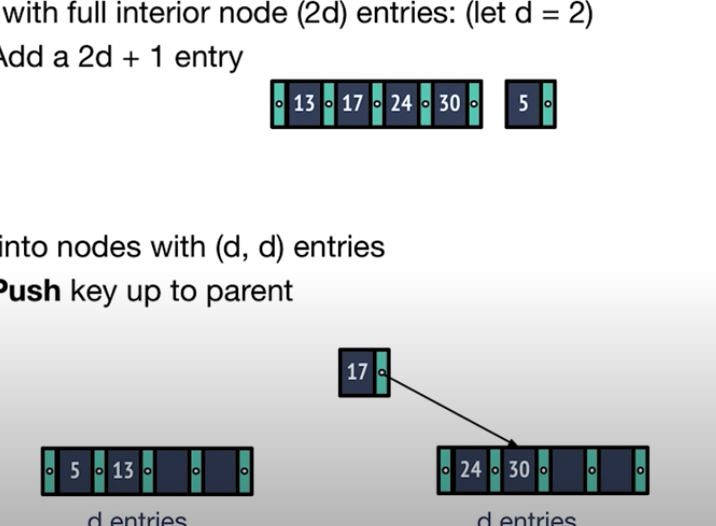
- 리프 노드가 아닌 중간 노드에 값을 추가하는 경우 리프노드와 분리하는 것은 비슷하지만, 중간값을 복사하는 것이 아니라, 위로 이동 시킨다는 차이가 있다.
B+TREE 실습 사이트
-
다음은 B+TREE 를 조작할 수 있는 사이트이다. 직접 실습해볼 수 있어서 이해하기가 훨씬 수월하다.
B+TREE 벌크 로딩
-
이미 만들어진 테이블에 B+TREE 인덱스를 생성한다면 어떻게 할 것인가? 하나씩 데이터를 집어넣어서 인덱스를 만들 것인가?
-
이러한 방법은 효율적이지 않다. 왜냐하면 데이터를 넣을 때마다, 루트 노드를 통해서 검색을 해야하며, 데이터가 삽입되면서 많은 페이지들이 변경된다. 그리고 계속 해서 데이터를 하나씩 집어넣어야 하므로, 캐시를 활용할 수 없다.
-
따라서 데이터를 직접 넣기전에 레코드를 키를 기준으로 정렬하는 방법을 사용한다. 미리 정렬을 한다면, 데이터를 넣기 위해서 루트노드에 접근하지 않아도 된다. 따라서 우리는 모든 리프노드를 미리 생성한 다음에 중간 노드나, 루트 노드를 업데이트 할 수 있다.
-
만약 미리 생성한 리프 노드를 중간 노드에 추가하는 도중에 공간이 모자르다면 그때 중간 노드나 루트 노드를 분리해준다.
-
이러한 방식은 캐시를 좀 더 효율적으로 사용할 수 있게 해주고, 리프 노드를 효율적으로 사용할 수 있게 해준다. 그리고 리프 노드가 디스크 상에 순차적으로 저장이 되므로 매우 효율적이다.
참고 문헌
>> Home