- 파일은 페이지의 집합으로 구성이 되는데 페이지를 구성하는 많은 방식이 있다. 그 중에서 정렬되지 않은 힙 파일 구조에 대해서 자세히 살펴볼 것이다.
파일, 페이지, 레코드
-
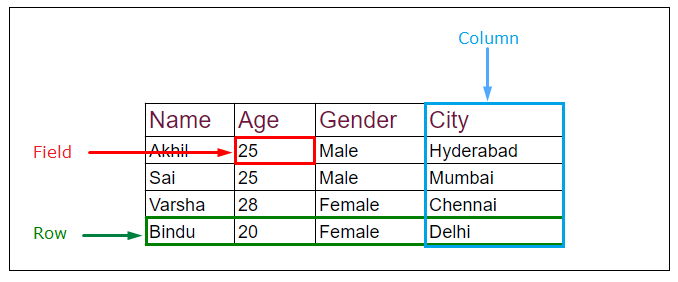
우리가 흔하게 볼 수 있는 데이터베이스에서 데이터가 어떻게 저장되는지 확인하는 방식은 위의 그림과 같다.
-
위와 같은 테이블은 파일의 형태로 저장이 된다. 파일은 블록과 페이지로 이루어져있다.
-
또한 페이지는 레코드의 집합으로 이루어진 형태이다.
-
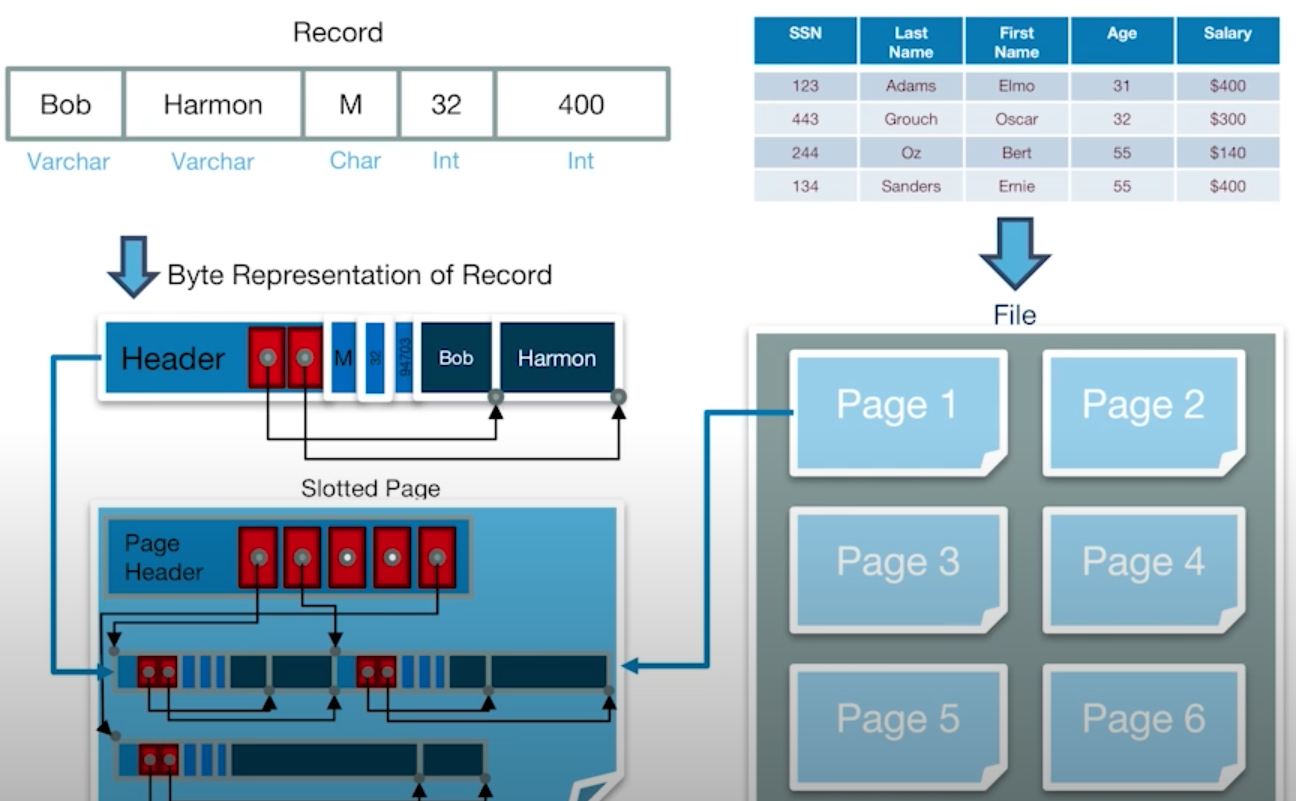
그리고 해당 블록과 페이지는 메모리상에서 다음과 같이 나타내진다.
-
페이지는 메인 메모리에서 레코드 형태로 나타내지고, 위의 그림과 같이 저장이 된다.
-
또한 쿼리를 통해서 조회문으로 레코드를 얻어오는 방식은 특정 레코드 아이디를 참조해서 얻어오는 것이다.
-
레코드 아이디는 (페이지 아이디, 페이지의 위치) 같은 것을 가리키는 포인터라고 생각하면 된다.
데이터베이스 파일 구조
정렬되지 않은 힙 파일 구조
- 레코드가 임의의 페이지에 저장된 상태, 순서가 따로 존재하지 않는다.
- 가장 단순한 구조로서 일반적으로 레코드들이 삽입된 순서대로 파일에 저장된다.
- 자료구조에서 나오는 힙과는 다르다. 데이터베이스에서 힙 파일 구조는 레코드들이 정렬되지 않은 상태라고 보면 된다.
- 페이지가 할당/해제 될 때마다 파일의 크기가 커졌다가 줄어든다.
- 레코드 수준의 연산을 지원한다. 페이지들과, 사용되지 않는 빈 공간, 그리고 페이지에 있는 레코드들을 추적해야한다.
-
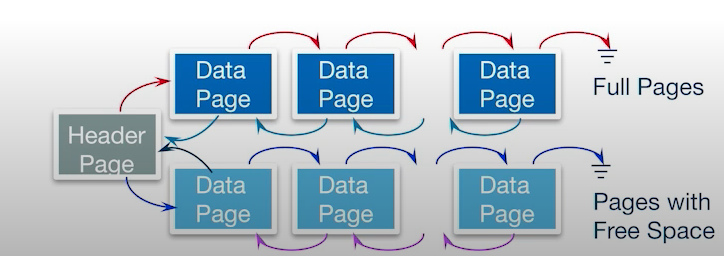
위의 그림은 힙 파일 구조를 링크드 리스트 형태로 구현한 것이다. 맨 앞에 헤더 페이지가 있는데 헤더 페이지 아이디와 힙 파일의 이름은 데이터베이스 카탈로그에 저장이 된다.
-
모든 페이지는 두 개의 포인터를 가지고 있다. 하나는 데이터를 가리키고 있는 포인터이고 다른 하나는 빈 공간을 가리키고 있는 포인터이다. 이 구조의 문제점은 페이지에 20 바이트를 추가하려고 할 때, 모든 페이지를 조회해서 20 바이트의 빈 공간을 가진 페이지를 찾아야 한다는 점이다.
-
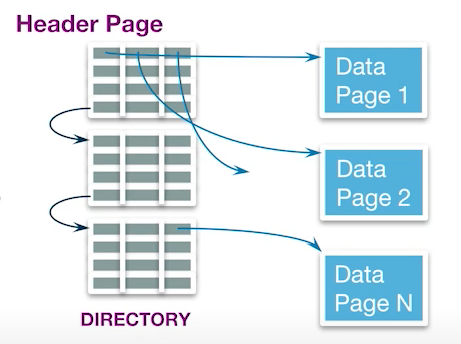
따라서 페이지 딕셔너리 방식을 사용 한다. 페이지 딕셔너리 방식은 많은 수의 헤더 페이지를 가진다. 첫 번째 헤더 페이지가 데이터베이스 카탈로그에 저장되며 다른 헤더를 가리키고 있다. 따라서 이러한 헤더들을 디렉터리라고 부른다.
-
각 헤더 페이지들은 실제 데이터가 저장되어 있는 페이지를 가리키는 공간을 가지고 있다.
-
이 방식을 사용하면 사용하지 않는 빈 공간을 쉽게 찾을 수 있어 새로운 데이터를 삽입하는데 전체 페이지를 검색하지 않아도 된다.
클러스터된 힙 파일
- 레코드와 페이지가 그룹화된 형태
정렬된 파일
- 페이지와 레코드가 정렬된 형태
인덱스 파일
- B+트리, 선형 해시 구조, …
- 레코드를 포함하거나, 다른 파일의 레코드를 가리킬 수 도 있다.
참고 문헌
>> Home