데이터 정규화란
-
머신러닝에 사용되는 데이터는 그 값이 너무 크거나 작지 않고 적당한 범위 (-1에서 ~ 1사이)에 있어야 모델의 정확도가 높아진다고 알려져있다.
-
이 기법은 알고리즘에 따라서 다른데, 선형회귀, 로지스틱 회귀, 서포트 벡터 머신 등의 알고리즘에서는 효과가 좋지만, 결정 트리 알고리즘에서는 효과가 없다.
-
그래서 학습 전에 미리 값이 적당한 범위를 유지하도록 모델에 입력할 데이터를 변환하기도 한다. 이러한 작업을 데이터 정규화라고 한다.
-
정규화에서 많이 쓰이는 기법은 정규화와 표준화이다. 각 기법의 의미와 변환 방법은 다음과 같다.
정규화 (normalization)
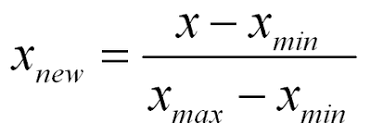
- 입력 변수 X를 최소값은 0, 최댓값은 1이 되게 1차 함수를 통해서 변환한다.
표준화 (standardization)
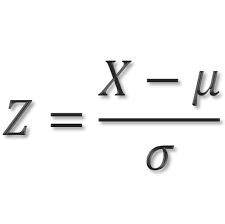
- 입력 변수 X를 평균이 0, 분산이 1인 정규 분포가 되도록 1차 함수를 통해서 변환한다.
중요한 점
-
두 가지 기법중에 정규화는 이상값의 영향을 쉽게 받는다. 따라서, 데이터에 이상값이 포함되었을 가능성이 높다면, 표준화를 적용하면 된다.
-
반대로. 이미지 데이터처럼 최솟값과 최대값을 미리 알 수 있는 경우에는 정규화를 사용하는 경우가 많다.
그 외의 데이터 전처리 방법
-
그 외 데이터 전처리에서 자주 쓰이는 기법으로 ‘이산화(discretization)‘이 있다.
-
이산화는 ‘연령’과 같은 숫자 값 데이터를 ‘10대’, ‘20대’와 같이 레이블로 분류하는 기법을 말한다.
-
그 이외에도 다양한 데이터 전처리 기법이 있다. 예를 들면 기업의 연간 매출처럼 기업의 규모에 따라서 값이 크게 달라지는 숫자 값은 그 로그값을 취해서 사용한다.
-
또 변환의 주기성이 알려진 숫자 함수라면 삼각함수가 유용하게 쓰이기도 한다. 경우에 따라서는 여러 개의 입력 데이터를 조합해 만든 새로운 입력 데이터를 이용하여 정확도가 뛰어난 모델을 만들기도 한다.
-
이러한 고도의 데이터 전처리를 ‘특징값 엔지니어링’이라고 하며 데이터 사이언티스트의 담당 업무 중에서도 가장 난도가 높은 업무로 취급이 된다.
참고 문헌
>> Home