정렬 알고리즘
-
정렬은 알고리즘 학습에 있어서 가장 기본적으로 알아두어야 하는 개념중에 하나이다.
-
정렬을 하면서 다양한 문제를 쉽게 해결할 수 있다.
- 찾기 : 정렬된 리스트는 특정 아이템을 쉽게 찾을 수 있도록 한다.
- 선택: 찾기와 마찬가지로 정렬된 리스트에서 다양한 아이템에 접근하여 얻어올 수 있다. 예를 들어서 리스트에서 3번째 큰 수를 가져온다던가 중간값을 찾거나 하는 일들이 쉽게 처리 될 수 있다.
- 중복 검출 : 정렬되어 있다면 중복 아이템 찾기도 쉽게 처리할 수 있다.
- 분포 : 리스트에서 가장 많이 있거나 적게 있는 아이템들을 쉽게 골라낼 수 있다.
거품 정렬 (Bubble Sort)
-
거품 정렬은 정렬 중에서 가장 직관적인 정렬 방식이다. 거품 정렬은 알고리즘 동작이 각 순회의 가장 큰 요소가 맨 뒤로 이동하는 방식이기 때문에 지어진 이름이다.
-
예를 들어서 배열에 요소가 다음과 같이 있다고 가정을 하자. [8, 2, 6, 4, 5] 그렇다면 가장 처음에 있는 요소를 뒤의 요소와 비교하여 뒤의 요소보다 크다면 서로 값을 바꾼다.
-
교환된 요소는 뒤의 숫자보다 크므로 계속 비교되어 끝까지 이동하게 된다.
-
한 번의 순회가 끝나면 다음 순회를 이어서 진행한다. 거품 정렬에서 1번의 순회는 가장 큰 수를 맨 뒤로 보내기 때문에 마지막 요소와 비교할 필요가 없다.
def bubble_sort(arr):
n = len(arr)
for i in range(n):
done_sort = True
for j in range(n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
done_sort = False
if done_sort:
break
return arr
if __name__ == "__main__":
input_arr = [8, 2, 6, 4, 5]
print(f'{bubble_sort(input_arr)}')
-
시간 복잡도는 최악의 경우와 평균적인 경우
O(N^2)가 된다. -
done_sort플래그로 인해서 이미 정렬된 배열을 정렬하는 경우 한 번의 순회만 진행하므로O(N)이 된다.
삽입 정렬 (Insertion Sort)
-
거품 정렬과 비슷하게 삽입 정렬도 직관적인 구현으로 이해하기 쉽다.
-
거품 정렬과는 다르게 리스트 내 하나의 요소를 선택하여 다른 요소와 비교하여 알맞은 위치에 삽입하는 정렬이다.
def insertion_sort(arr):
n = len(arr)
for i in range(1, n):
key_item = arr[i]
j = i - 1
while j >= 0 and arr[j] > key_item:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key_item
return arr
-
거품 정렬과 삽입 정렬의 시간 복잡도는 동일하기 때문에 같은 성능으 가진 알고리즘으로 판단할 수 있는데 실제 데이터를 입력해보고 확인하면 평균적으로 삽입 정렬이 거품 정렬보다 비교 횟수가 적다는 것을 알 수 있다.
-
삽입 정렬의 시간 복잡도가 높아 거품 정렬과 함께 실제로는 사용되지 않을 것이라고 생각할 수 있는데, 하지만 삽입 정렬은 적은 데이터 개수를 가지는 데이터 셋에서 다른 정렬보다 평균적으로 좋은 성능을 가진다.
-
그래서 파이썬, 자바, 최신 C++에 사용되는 내장 정렬 함수는 작은 데이터 셋에 대해서 삽입 정렬을 사용하도록 구혆되어 있다.
-
파이썬에서 사용하는 내장 함수
sorted()는 팀 정렬이라는 정렬 기법으로 병합 정렬과 삽입 정렬을 선택적으로 사용하도록 구현되어 있다.
병합 정렬 (Merge Sort)
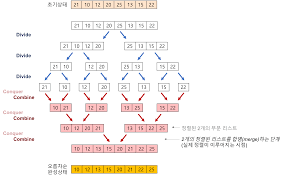
-
거품 정렬과 삽입 정렬보다 높은 효율을 보이는 정렬 알고리즘이다. 병합 정렬은 분할 정복 접근을 기반으로 복잡한 문제를 해결 할 때 사용하는 강력한 알고리즘 기술이다.
-
분할 정복을 이해하기 위해서는 재귀를 이해하는 것이 필요하다. 재귀는 분할 정복이 필요한 문제를 해결 가능한 하위 문제로 쪼갤 수 있는 방법을 제공한다.
-
분할 정복은 기본적으로 문제를 작게 만들어 해결하고, 해결된 결과를 다음 하위 문제로 전달 후에 전체 문제를 해결하려고 시도하는 것이다.
def merge_sort(arr):
def merge(left, right):
left_len = len(left)
right_len = len(right)
result = []
left_index = right_index = 0
while len(result) < left_len + right_len:
if left[left_index] <= right[right_index]:
result.append(left[left_index])
left_index += 1
else:
result.append(right[right_index])
right_index += 1
if right_index == right_len:
result.extend(left[left_index:])
break
if left_index == left_len:
result.extend(right[right_index:])
break
return result
n = len(arr)
if n < 2:
return arr
mid_index = n // 2
left = merge_sort(arr[:mid_index])
right = merge_sort(arr[mid_index:])
return merge(left, right)
- 병합 정렬은 O(nlogn)의 시간 복잡도를 안정적으로 지원한다.
퀵 정렬(Quick Sort)
-
병합 정렬과 비슷하게 분할 정복 방법을 이용한 방식이다.
-
다른 점은 입력 리스트를 두 리스트로 나눌 때 한쪽은 특정 값보다 작은 값만 모으고 다른 하나는 특정 값보다 큰 값만 모은다. 이를 재귀적으로 완전히 정렬이 될 때까지 진행한다.
-
특정 값을 퀵 정렬에서 피벗이라고 부르는데 피벗을 결정하는 방식에 따라서 성능 차이가 발생한다.
-
입력 리스트를 나누는 것을 파티셔닝이라고 부른다. 분할할 때마다 피벗을 선택하여 두 부류 (작은 값 - LOW, 큰 값 - HIGH)로 나누는 작업을 한다.
-
각 파티셔닝마다 피벗 값을 결정해야하는데 많은 고민이 필요하다. 만약 피벗 값이 리스트 마지막 요소로 선택되어있는 경우, 이미 정렬된 리스트라면 계속 작은 값에 남은 요소가 다 들어가게 되므로 시간 복잡도가 O(N^2)이 된다.
-
이것을 방지하기 위해서 무작위로 피벗을 결정하여 최악의 경우를 최소화하는 방향이나 중간 값을 찾아서 LOW / HIGH 분배를 하면 안정적으로 O(nlogn)의 시간 복잡도를 가질 수 있다.
def quicksort(arr):
arr_len = len(arr)
if arr_len < 2:
return arr
low, same, high = [], [], []
pivot = arr[randint(0, arr_len - 1)]
for item in arr:
if item < pivot:
low.append(item)
elif item == pivot:
same.append(item)
elif item > pivot:
high.append(item)
return quicksort(low) + same + quicksort(high)
-
극단적으로 임의 값이 매번 가장 작은 값이거나 가장 큰 값이라면, N번 분리되고 N번 합치는 과정이 필요하여 최악의 경우에는 O(N^2)이 되지만 평균적으로는 O(nlogn)이 되는 정렬 알고리즘이다.
-
이러한 최악의 상황으로는 정렬 성능이 나오지 않기 때문에 피벗을 선택할 때 무조건 중앙 값으로 선택할 수 있다면 LOW, HIGH가 정확히 반으로 나누어지기 때문에 O(nlogn)을 유지할 수 있다.
팀 정렬(Tim Sort)
-
팀 정렬은 기존의 알고리즘의 특징을 잘 파악하고 최적으로 조합하여 탄생한 알고리즘이라고 할 수 있다.
-
팀 정렬은 삽입 정렬과 병합 정렬을 섞어서 사용한다. 다만 삽입 정렬의 비교 연산을 줄이기 위해서 선택된 요소의 알맞은 위치 탐색을 선형 탐색이 아닌 이진 탐색으로 하고 이 위치에 요소 삽입을 진행한다.
-
당연한 이야기지만 선형 탐색은 O(N)이고 이진 탐색의 요소는 O(logN)이기 때문에 더 성능이 좋다.
-
이제 살펴봐야하는 팀 정렬의 키워드는 런이다. 데이터 셋이 적다면 (32개 혹은 64개 이하) 이진 삽입 정렬만으로 정렬해도 충분히 빨리 하겠지만, 그보다 큰 개수의 데이터라면 팀 정렬은 런 단위로 나누어서 이진 삽입 정렬을 진행하고 모두 완료되면 병합 정렬한다.
-
막연하게 특정 개수로 런을 나누는 것이 아니라 규칙이 있다. 앞의 삽입 정렬은 이미 정렬되었거나 거의 정렬된 상태에서 빠르게 완료되는 정렬이다.
-
팀 정렬의 최소 런 값은 보통 64나 32로 설정하여 구성한다. 배열의 요소를 확인하면서 오름차순이나 내림차순으로 정렬된 구간을 최소 런 값에 맞춰서 구성할 수 있다. 예를 들어서 특정 구간의 요소의 오름차순으로 정렬된 개수가 24개라고 하자. 그리고 최소 런(min run)의 개수는 64개로 설정되어 있다면, 그 뒤에 따르는 40개의 요소를 하나로 묶어 런을 구성한다.
-
이진 삽입 정렬은 어느정도 정렬이 되어 있는 배열을 정렬할 때 좋은 성능을 발휘하므로 최소 런의 개수를 64개 혹은 32개로 하는 것이다.
-
아래는 팀정렬을 간소하게 구현해본 예제이다. 실제 사용되고 있는 팀 정렬 알고리즘을 살펴보면 설명한 내용 이외에도 성능을 높이기 위한 내용이 추가적으로 더 포함된다.
def binary_search(arr, key, start, end):
if end - start <= 1:
if arr[start] > key:
return start - 1
else:
return start
mid = (start + end) // 2
if arr[mid] < key:
return binary_search(arr, key, mid, end)
elif arr[mid] > key:
return binary_search(arr, key, start, mid)
else:
return mid
def insertion_sort(arr, run_s=0, run_e=None):
if run_e is None:
run_e = len(arr) - 1
for i in range(run_s + 1, run_e + 1):
v = arr[i]
pos = binary_search(arr, v, run_s, i) + 1
for k in range(i, pos, -1):
arr[k] = arr[k - 1]
arr[pos] = v
def timsort(arr):
def merge(left, right):
left_len = len(left)
right_len = len(right)
result = []
left_index = right_index = 0
while len(result) < left_len + right_len:
if left[left_index] <= right[right_index]:
result.append(left[left_index])
left_index += 1
else:
result.append(right[right_index])
right_index += 1
if right_index == right_len:
result.extend(left[left_index:])
break
if left_index == left_len:
result.extend(right[right_index:])
break
return result
min_run = 32
n = len(arr)
for i in range(0, n, min_run):
insertion_sort(arr, i, min((i + min_run - 1), n - 1))
size = min_run
while size < n:
for start in range(0, n, size * 2):
mid = start + size - 1
end = min((start + size * 2 - 1), (n - 1))
merged = merge(arr[start:mid + 1], arr[mid + 1:end + 1])
arr[start:start + len(merged)] = merged
size *= 2
return arr
-
최소 런의 개수를 32개로 정했다. 데이터를 많이 가져갈 것이 아니기 때문에 32개로 지정하여 과정을 살펴보자.
-
가장 먼저 32개 만큼 배열을 건너 뛰면서 앞서 구현한 이진 삽입 정렬을 호출한다. 만약 100 개의 요소가 있는 배열을 정렬한다면 인덱스를 기준으로 0 ~ 31, 32 ~ 63, 64 ~ 95, 96 ~ 99으로 구간이 나누어지고 각 구간은 이진 삽입 정렬로 정렬된다.
-
이 정렬은 2개씩 짝을 지어서
merge()함수를 호출하는데 처음 0 ~ 31과 32 ~ 64 구간이 합쳐지고 원본 배열이 업데이트 되면 64 ~ 95와 96 ~ 99 구간이 병합이 진행된다. 앞 두 구간이 업데이트 되었으므로 합쳐진 64개의 구간이 병합되어야 한다.