스레드
-
스레드는 독립적으로 수행되는 작업의 단위이다. 일반적인 프로세스 기반 프로그램은
main()함수의 순차적인 흐름에 따라 코드에 맞는 작업을 수행하고 종료하는 식의 프로그램이었다. 스레드는 다수의 독립된 작업흐름을 가진다. -
실행중인 프로세스는 CPU, 메모리 등 시스템 자원을 할당 받아 작업을 수행한다.일반적인 환경이라면 CPU의 수 보다 더 많은 프로세스가 실행되고 있기 때문에 각각의 프로세스는 운영체제의 작업 스케줄러에 의해서 시스템 자원의 사용 순서를 기다린 후에 자원을 할당 받아서 실행된다.
-
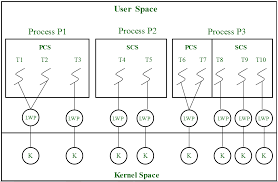
그런데 작업 스케줄러는 실제로 프로세스 단위가 아니라 스레드 단위로 스케줄링을 한다. 따라서 스레드는 독립적인 작업의 흐름을 가질 수 있다.
-
위의 그림처럼 스케줄러는 스레드 단위로 작업 순서를 결정한다. 또한 같은 프로세스에 속한 스레드들은 전역 변수와 같은 프로세스의 자원을 공유할 수 있다.
스레드의 생성
기본적으로 프로그램은 하나의 스레드로 구성되어 있다. 여기에 추가의 작업 흐름을 만들기 위해서는 pthread_create() 함수를 호출하면 된다.
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_r *attr, void *(start_routine)(void *), void *arg);
인자
- thread: 스레드를 지칭하기 위한 스레드 ID
- attr: 스레드 생성시 필요한 속성값을 저장하고 있는 구조체, 일반적으로 NULL로 설정한다.
- start_routine: 스레드의 시작과 함께 호출되는 함수의 포인터
- arg: start_routinue 함수에 전해지는 매개변수, 매개변수가 없을 경우에는 NULL로 셋팅한다.
결과값
-
성공시 0, 실패 시 정의된 에러 번호
-
pthread_create()함수가 스레드 생성에 실패하면 그 원인에 해당하는 에러 코드를 반환한다. -
EAGAIN: 스레드를 생성하기 위한 가용성의 부족
-
EINVAL: 잘못된 attr 셋팅
-
EPERM: 접근권한 에러
데이터, 힙, 스택 그리고 스레드
-
프로세스는 운영체제로부터 가상 메모리 영역을 할당받고 코드부터 시작하여 실행을 위해 사용되는 변수들까지 그 메모리 영역에 저장한다. 이 중에서 실제로 변수를 저장하기 위한 영역에는 다음과 같은 이름이 있다.
-
데이터 영역: 전역 변수와 정적 변수까지 지정되는 영역이며 프로그램의 시작과 동시에 할당된다.
-
스택 영역: 지역 변수가 지정되는 영역이다. 함수가 호출되면 함수에서 사용하는 지역 변수들은 이 영역에서 할당된다.
-
힙 영역: 실행 시에 지정되는 영역이다. 프로그래머에 의한 동적 할당 함수가 호출되면 이 영역에 있는 메모리 공간이 사용된다.
-
fork()함수를 이용하여 프로세스를 복제하면 새로 생성된 자식 프로세스는 부모 프로세스의 데이터, 스택, 힙 영역이 모두 복사되어 새로운 프로세스로 동작한다. 반면 스레드가 생성된 경우에는 스택 영역만 추가로 생성된다.
스레드 예제
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
void *init_thread(void *perm) {
int i;
for (i = 1; i < 10; i++) {
printf("counter: %d\n", i);
sleep(1);
}
printf("thread is now terminated. \n");
}
int main(int argc, char *argv[]) {
pthread_t thread_id;
if (pthread_create(&thread_id, NULL, init_thread, NULL) != 0) {
fprintf(stderr, "pthread creation error\n");
exit(0);
}
sleep(5);
printf("main function is terminated.\n");
return 0;
}

-
실행 결과 생성된 스레드가 카운터를 1에서부터 5까지 증가시키면서 화면에 출력한다.
-
스레드가 종료되는 시점은 메인 함수가 종료되는 시점과 같다는 것을 확인할 수 있었다.
-
스레드는 실행할 것이 더 남이있다고 하더라도 메인 함수가 종료되면 함께 종료된다.
-
만약 스레드의 정상적인 종료를 기다리는 로직이 메인 함수에게 요구 된다면 어떻게 할 수 있을까?
-
스레드가 종료되는 시점을 예측하여 메인 함수를 대기 시키는 방법이 있을 수 있으나, 이는 코드가 복잡해질 수록 힘들다.
-
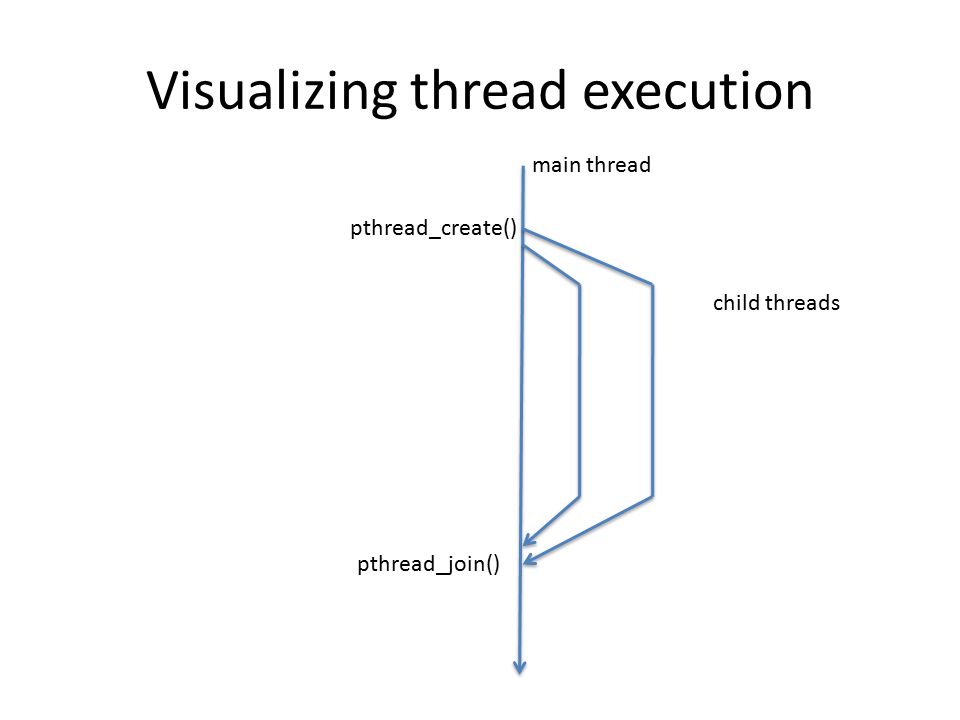
따라서
pthread_join()이라는 함수를 제공한다.pthread_join()함수는 지정된 스레드가 종료할 때까지pthread_join()을 호출한 스레드를 대기 상태로 만든다. -
메인 함수에서
pthread_join()을 호출하면 지정한 스레드의 종료 시점까지 메인 함수를 대기 상태로 만들 수 있다.
int pthread_join(pthread_t thread, void **retval);
인자
- thread: 종료를 기다리는 스레드의 ID
- retval: 스레드가 종료하면서 반환하는 값에 접근하기 위한 2차원 포인터
결과값
- 성공시 0, 실패시 에러코드를 반환한다.
pthread_join() 함수는 실패 시 다음과 같은 에러코드를 반환한다.
- EDEADLK: 두 스레드가 서로
pthread_join()을 호출하는 교착상태의 발생 - ESRCH: 해당 ID를 갖는 스레드가 존재하지 않을 경우
예제
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
void *init_thread(void *perm) {
int i;
for (i = 0; i < 10; i++) {
printf("counter: %d\n", i);
sleep(1);
}
printf("thread is now terminated. \n");
}
int main(int argc, char *argv[]) {
pthread_t thread_id;
int res;
if (pthread_create(&thread_id, NULL, init_thread, NULL) != 0) {
fprintf(stderr, "pthread creation error\n");
exit(0);
}
if (pthread_join(thread_id, (void **)&res) != 0) {
fprintf(stderr, "pthread join error\n");
exit(0);
}
printf("main function is terminated\n");
return 0;
}

- 실행결과 스레드가 종료되기 전까지는 메인 함수가 종료되지 않는 것을 확인할 수 있다.
스레드 사이의 통신
-
같은 프로세스 안에서 존재하는 스레드 사이의 정보 교환 방법에 대해서 알아볼 것이다.
-
결론부터 말하자면 스레드 사이의 정보 교환을 위해서 프로세스의 전역 변수가 사용된다.
fork()함수로 복제하여 생성한 프로세스와는 달리 스레드는 한 프로세스 내에서 독립적인 동작의 흐름을 만드는 것이기 때문에 프로세스의 자원을 공유할 수 있다. -
다만, 스레드 사이의 데이터 동기화가 중요하다. 동기화 문제는 프로세스에서는 새마포어를 사용해서 해결하였는데 스레드도 세마포어를 이용하여 문제를 해결해볼 것이다.
예제
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#define SEM_NAME "/test"
void *thread_a_main(void *arg);
void *thread_b_main(void *arg);
static sem_t *sem;
static int counter = 0;
int main(int argc, char *argv[]) {
pthread_t thread_id_1, thread_id_2;
int res;
sem = sem_open(SEM_NAME, O_RDWR | O_CREAT, 0777, 1);
if (sem == SEM_FAILED) {
fprintf(stderr, "sem open error \n");
exit(1);
}
if (pthread_create(&thread_id_1, NULL, thread_a_main, NULL) != 0) {
fprintf(stderr, "pthread 1 creation error\n");
exit(0);
}
if (pthread_create(&thread_id_2, NULL, thread_b_main, NULL) != 0) {
fprintf(stderr, "pthread 2 creation error\n");
exit(0);
}
if (pthread_join(thread_id_1, (void **) &res) != 0) {
fprintf(stderr, "pthread 1 join error\n");
exit(0);
}
if (pthread_join(thread_id_2, (void **) &res) != 0) {
fprintf(stderr, "pthread 2 join error\n");
exit(0);
}
sem_unlink(SEM_NAME);
return 0;
}
void *thread_a_main(void *arg) {
int i;
for (i = 0; i < 60000; i++) {
sem_wait(sem);
counter += 2;
printf("thread a increases the counter by 2: counter - %d\n", counter);
sem_post(sem);
}
return NULL;
}
void *thread_b_main(void *arg) {
int i;
for (i = 0; i < 60000; i++) {
sem_wait(sem);
counter += 3;
printf("thread b increases the counter by 3: counter - %d \n", counter);
sem_post(sem);
}
return NULL;
}

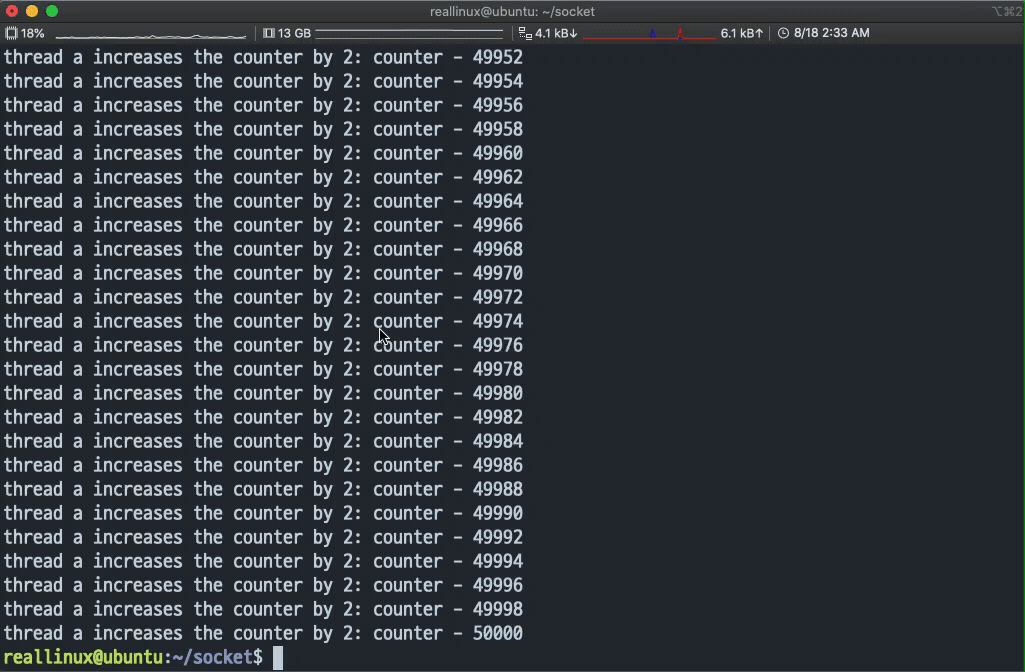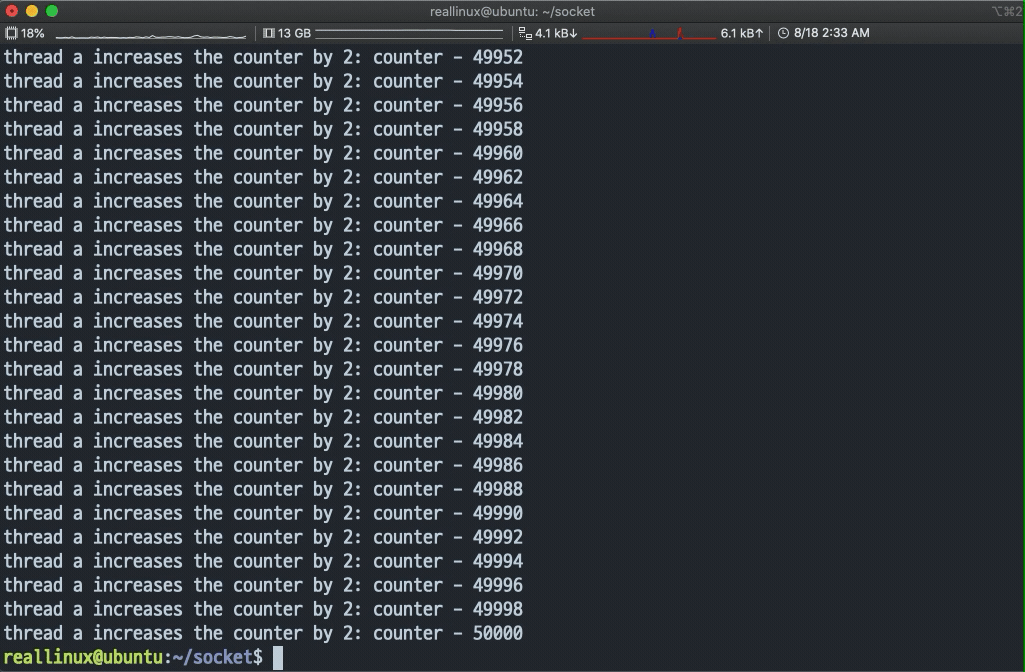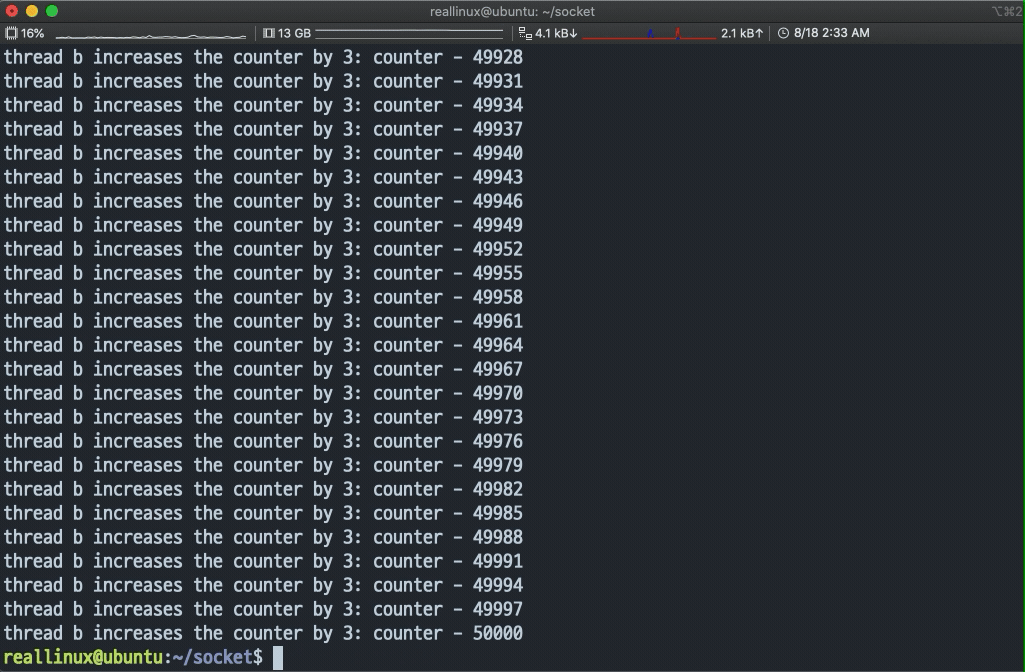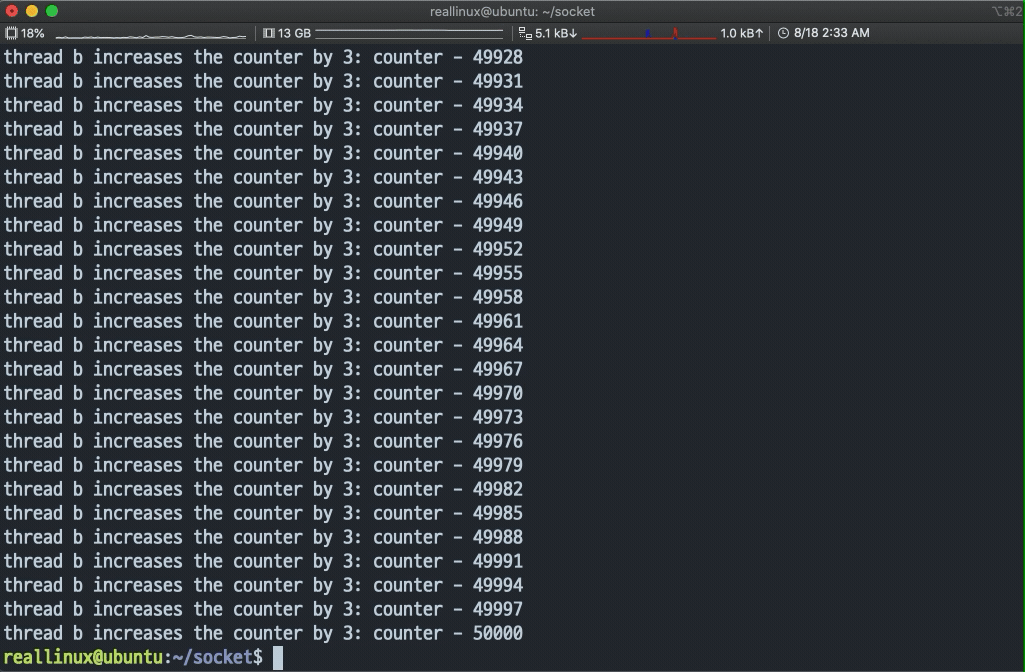
- 실행 결과 A, B 스레드가 각각 카운터 변수에 접근해서 값을 증가시키는 것을 확인할 수 있다.
뮤텍스를 이용한 데이터 동기화
-
위의 예제와 같은 동기화 문제를
pthread.h에 있는 뮤텍스를 활용하여 해결할 수 도 있다. -
뮤텍스도 세마포어와 유사한 기능을 수행한다. 세마포어와 마찬가지로 생성, 크리티컬 섹션 진입, 크리티컬 섹션 탈출, 소멸을 담당하는 함수를 알아보면서 뮤텍스 예제를 만들어 볼 것이다.
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *mutexattr);
인자
- mutex: 생성한 뮤텍스 객체에 접근하기 위한 포인터
- mutexattr: 뮤텍스 객체의 속성을 정하기 위한 인자, NULL을 사용하면 기본값으로 설정
결과값
-
성공시 0, 실패시 에러코드를 반환한다.
-
pthread_mutex_init()함수는 뮤텍스 객체를 생성하는 역할을 한다. 생성한 뮤텍스 객체에 접근하는 것을 가능하게 하기 위해서mutex라는pthread_mutex_t타입의 포인터를 인자로 받는다. -
세마포어와 마찬가지로 뮤텍스 자체가 크리티컬 섹션을 보호하는 것은 아니다. 스레드의 상태 정보를 공유할 수 있는 게시판으로 뮤텍스를 이해하는 것이 좋다.
-
동기화를 하고자 하는 변수에 대한 읽기 작업/쓰기 작업을 하기 전에 항상 게시판을 확인하여 현재 사용중인 스레드가 있는지 확인하는 과정이 뮤텍스이다.
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
-
동기화하기 위한 자원에 접근하기 전에 호출하는 함수는
pthread_mutex_lock()함수이다. -
반면 자원에 대한 사용을 멈추고 다른 프로세스가 사용할 수 있는 기회를 주는 함수는
pthread_mutex_unlock()이다.
int pthread_mutex_destory(pthread_mutex_t *mutex);
인자
-
mutex: 사용할 뮤텍스 객체를 가리키는 포인터
-
마지막으로 생성한 뮤텍스를 소멸시킬 때 사용하는
pthread_mutex_destory()이다.
예제
- 뮤텍스를 이용하여 스레드 간에 동기화를 시켜보겠다.
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
void *thread_a_main(void *arg);
void *thread_b_main(void *arg);
static int counter = 0;
static pthread_mutex_t mutex;
int main(int argc, char *argv[]) {
pthread_t thread_id_1, thread_id_2;
int res;
pthread_mutex_init(&mutex, NULL);
pthread_create(&thread_id_1, NULL, thread_a_main, NULL);
pthread_create(&thread_id_2, NULL, thread_b_main, NULL);
pthread_join(thread_id_1, (void**) &res);
pthread_join(thread_id_2, (void**) &res);
pthread_mutex_destroy(&mutex);
return 0;
}
void *thread_a_main(void *arg) {
int i;
for (i = 0; i < 10000; i++) {
pthread_mutex_lock(&mutex);
counter += 2;
printf("thread a increases the counter by 2: counter - %d\n", counter);
pthread_mutex_unlock(&mutex);
}
return NULL;
}
void *thread_b_main(void *arg) {
int i;
for (i = 0; i < 10000; i++) {
pthread_mutex_lock(&mutex);
counter += 3;
printf("thread b increases the counter by 3: counter - %d\n", counter);
pthread_mutex_unlock(&mutex);
}
return NULL;
}
참고 문헌
>> Home